GAN (Generative Adversarial Network) 이란?
‘Adversarial’이란 단어의 사전적 의미를 보면 대립하는, 적대하는 뜻을 갖는다. 이렇게 적대/대립을 하려면 상대방이 있어야 가능하다는 것을 크게 두 부분으로 나누어져 있다는 것을 알 수 있다
GAN은 다양한 노이즈 (Noise) 입력을 받아 원하는 카테고리의 기존에 존재하지 않는 새로운 이미지를 생성하는 생성(Generative) 네트워크와 생성된 이미지가 가까인지 진짜인지를 판별하는 판별(Discriminative) 네트워크를 적대적으로 (Adversarial) 학습시키며, 입력 이미지나 비디오를 다른 형태나 정보를 지닌 이미지나 비디오를 다른 형태나 정보를 지닌 이미지 또는 비디오로 변환하는 모델이다.
예를들어 두 모델을 각각 모델 A, 모델 B라고하면, 모델 A는 학습된 모델 B의 취약점을 찾아 교란하도록 학습하고 모델 B는 탐색된 취약점을 보완하는 방향으로 학습을 진행하는 방법론입니다.이렇게 생성된 데이터는 정해진 라벨이 없기 때문에 비지도 학습(unsupervised-training) 기반 생성 모델로 분류 된다.
최근 적대적 생성 신경망을 활용한 이미지 생성 및 변환 기술에 관한 연구가 더욱 활발해지고 있다. 초기의 GAN은 noise와 같은 의미 없는 정보에서 다양한 이미지를 생성하는 기술이 대부분이였다.
초기 GAN 모델의 문제점
- 128 x 128 의 해상도
- noise로부터 생성된 이미지는 생성이 완료되기 전까지 어떤 모습일지 전혀 예측할 수 없다
Gan은 크게 2가지 모델로 이루어져 있다 . Generator와 Discriminator로 이루어져 이루어져 있어 동시에 두 개의 모델을 훈련하는 것이 특징이다. 여기서 z라고 하는 것은 랜덤 벡터 z를 의미하는 것으로 오른쪽 그림의 uniform distribution이나 normal distribution을 따른다고 한다.
이 랜덤 벡터 z를 Generator의 입력으로 넣어 Fake를 생성한다. 이후 Real의 경우 실제 데이터셋을 의미하는 것으로 생성된 Fake와 실제 Real 이미지를 Discriminator의 입력으로 넣게 되면 Fake 또는 Real이라고 출력하게 된다. GAN은 최종 출력인 Fake와 Real의 확률이 1/2에 수렴하여 진짜와 가짜를 구분할 수 없도록 학습하게 된다. GAN을 더욱 이해하기 위해서는 확률밀도함수의 개념을 알아야 한다. 아래는 어떤 모종의 확률밀도함수를 나타내는 그래프이다.
처음 GAN을 제안한 이안 굿 펠로는 GAN을 경찰과 위조지폐범 사이의 게임에 비유

위조지폐범은 최대한 진짜 같은 화폐를 만들어(생성) 경찰을 속이기 위해 노력하고, 경찰은 진짜 화폐와 가짜 화폐를 완벽히 판별(분류)하여 위조지폐범을 검거하는 것을 목표로 한다. 이러한 경쟁적인 학습이 지속되다 보면 어느 순간 위조지폐범은 진짜와 다를 바 없는 위조지폐를 만들 수 있게 되고 경찰이 위조지폐를 구별할 수 있는 확률도 가장 헷갈리는 50%로 수렴하게 되어 경찰은 위조지폐와 실제 화폐를 구분할 수 없는 상태에 이르게 된다.
경찰은 분류 모델, 위조지폐범은 생성 모델을 의미하며, GAN에는 최대한 진짜 같은 데이터를 생성하려는 생성 모델과 진짜와 가짜를 판별하려는 분류 모델이 각각 존재하여 서로 적대적으로 학습시킨다.

이처럼 적대적 학습에서는 분류 모델을 학습 시킨 후, 생성 모델을 학습 시키는 과정을 서로 주고 받으면서 반복한다. 분류 모델의 학습은 크게 두가지 단계로 이루어져 있다. 하나는 진짜 데이터를 입력해서 네트워크가 해당 데이터를 진짜로 분리하도록 학습 시키는 과정이고 두 번째는 첫 번째와 반대로 생성 모델에서 생성한 가짜 데이터를 입력해서 해당 데이터를 가짜로 분리하도록 학습하는 과정이다.
이 과정을 통해 분류 모델은 진짜 데이터를 진짜로, 가짜 데이터를 가짜 데이터로 분류 할 수 있게 된다.
분류 모델을 학습 시킨 다음에는 학습된 분류 모델을 속이는 방향으로 생성 모델을 학습 시켜줘야 한다. 생성 모델에서 만들어낸 가짜 데이터를 진짜라고 분류할 만큼 데이터와 유사한 데이터를 만들어 내도록 생성 모델을 학습 시킨다.
GAN 파생 모델

DCGAN(Deep Convolutional Generative Adversarial Network)
- [Paper] : https://arxiv.org/pdf/1511.06434.pdf
DCGAN은 위에서 기술한 GAN에서 직접적으로 파생된 모델로, 생성자와 구분자에서 합성곱 신경망(Convolution)과 전치 합성곱 신경망 (Convolution-transpose)을 사용했다는 것이 차이점이다.
이전 Gan과 모델의 구조와 다른 점은 구분자에서는 convolution 계층, 배치 정규화(batch norm) 계층, 그리고 leaky Relu 활성화 함수가 사용되었고, 생성자에서는 convolutional-transpose 계층, 배치 정규화(batch norm), 그리고 ReLU 활성함수가 사용되었다.
입력 값은 역시 정규 분포에서 추출한 잠재공간 벡터 z이다. 이때 전치 합성곱 신경망은 잠재 공간 벡터로 하여금 이미지와 같은 차원을 갖도록 변환시켜주는 역할을 한다.
전치 합성곱 신경망은 합성곱 신경망의 반대적인 개념이라 이해하면 쉽고, 입력된 작은 CHW 데이터를 가중치들을 이용해 더 큰 CHW로 upsampling해주는 계층이다. 논문에서는 각종 최적화 방법이나 손실함수의 계산, 모델의 가중치 초기화 방법등에 관한 추가적인 정보들도 적어두어었다.

ACGAN (Auxiliary Classifier GAN)
- [Paper] : https://arxiv.org/pdf/1610.09585.pdf
ACGAN은 조건부 이미지 생성의 성능을 높이는 기법으로 판별기가 이미지의 클래스를 구분하도록 하는 학습을 추가 하게 된다. 이를 통해 CGAN에 비해서 보다 좋은 성능을 낼 수 있게 된다.

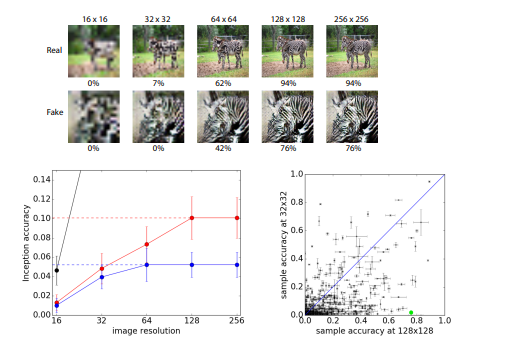


평가 지표
- **FID(Frechet Inception Distance) [Heusel et al. 2018]
- FID 를 측정할 때 inception Network 를 사용하게 된다는 걸 이름을 통해 알 수 있다
- pretrained 된 inception V3에서 출력 레이러를 제거하고 출력이 마지막 pooling layer어의 activation 을 사용
- 이 output layer에는 총 2048개의 activation 이 있으므로, 각 이미지 2048개의 특징 vector가 나온다
- inception score는 생성된 이미지만 사용하여 성능을 평가하는 반면, FID는 대상 도메인의 실제 이미지 모음 통계와 생성된 이미지 모음 통계를 비교해 평가를 진행한다
- FID 를 측정할 때 inception Network 를 사용하게 된다는 걸 이름을 통해 알 수 있다
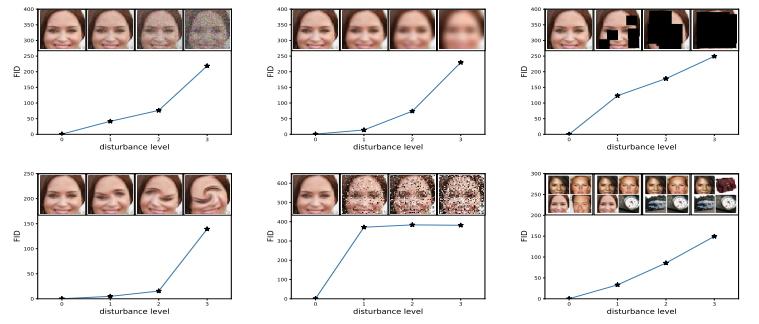
Reference [Compound Frechet Inception Distance for Quality Assessment of GAN Created Images]
'Machine-Learning > GAN (Generative Adversarial Network)' 카테고리의 다른 글
| [GAN] AutoEncoder의 모든 것 (Revisit Deep Neural Networks) (0) | 2022.10.18 |
|---|

댓글