An overview of gradient descent optimization algorithms
introduction
- Gradient descent algorithms
- Gradient descent
- 여러 종류의 문제에서 최적의 해법을 찾을 수 있는 일반적인 최적화 알고리즘
- 목적 함수의 기울기 와 반대 방향으로 parameter 쎄타를 업데이트하며 목적 함수 \(\triangledown\theta\)를 최소화 하는 방법이다
- learning rate (lr)
- parameter step의 크기
- lr가 너무 작으면 알고리즘이 수형하기 위해 반복을 많이 진행해야 하므로 시간이 오래 걸리고,
- lr가 너무 크면 골짜기를 가로 질러 반대편으로 건너뛰게 되어 이전보다 더 큰 값으로 발산 할 수 있다.
- Gradient descent

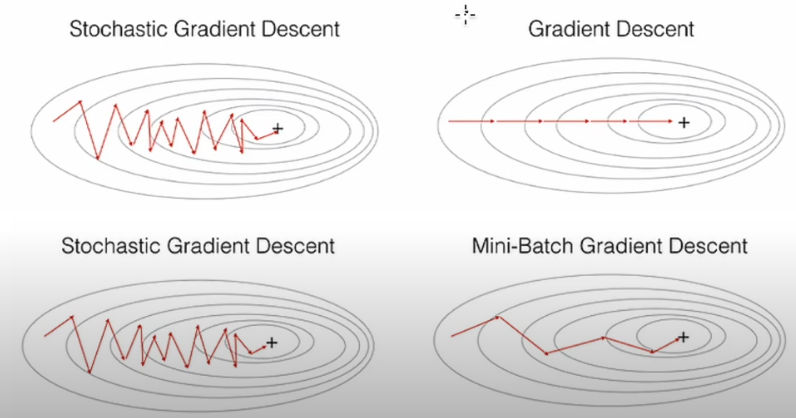
Gradient descent Variants
기본적인 Gradient descent 3가지 소개
GD ? 모든 자료를 다 검토해서 내 위치의 산 기울기를 계산해서 갈 방향을 찾겠다
Batch gradient descent
- 매 gradient descent step 마다 전체 dataset x에 대해 계산하는 방법

- 장점 : 특성 수에 민감하지 않다
- 단점 : 매우 느릴 수 있다
- 메모리에 맞지 않는 Dataset의 경우 다루기 어렵다.
- Online으로 model을 사용할 수 없다
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
Stochastic gradient descent (SGD)
- 각 training data x 및 label y에 대한 parameter를 업데이트 하는 방법이다

- 한번에 하나의 업데이트를 수행하며 중복성을 제거
- 매 step에서 다뤄야 할 data가 작기 때문에 빠르고 매우 큰 훈련 세트도 가능하며 online으로 model을 생성할 수 있다
- 지역 최솟값을 건너 뛰어 새롭고 잠재적으로 더 나은 지역 최솟값으로 이동할 수 있다

- 목적 함수가 크게 변동하도록 하는 높은 분산으로 빈번한 업데이트를 수행
- 반면에 SGD가 계속 오버 슈트하므로 궁극적으로 수렴에느 정확한 최소값으로 복잡하게 만든다
- local min에 빠지지 않고 global min으로 갈 수 있다
- 학습률을 천천히 낮추면 SGD는 배치 경사 하강 법과 동일한 수렵 동작
Mini-Batch gradient descent
Mini-Batch라 부르는 임의의 작은 sample set에 대해 gradient를 계산하는 방법

parameter 업데이트의 분산을 줄여 더 안정적인 수렴으로 이어질 수 있다
SGD라는 용어는 일반적으로 미니 배치를 사용할 때도 사용된다.
Momentum
스텝 계산해서 움직인 후 , 아까 내려오던 관성 방향 또 가자 ?
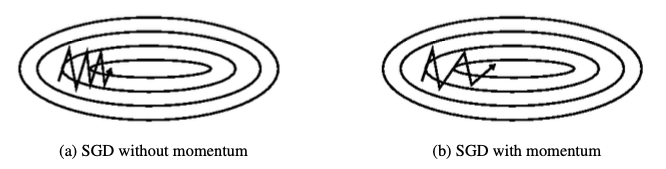
local minimum에 갖쳤다 , 이 것을 해결하기 위해서 나온 것이 Momentum
즉, SGD는 협곡, 즉 표면이 다른 차원보다 한 차원에서 훨씬 더 가파르게 구부러진 지역을 탐색하는데 문제가 있다

- Momentum은 gradient가 같은 방향을 가리키는 차원에 대해 증가하고 gradient가 방향을 변경하는 차원에 대한 업데이트를 줄인다
- 더 빠르게 평탄한 지역을 탈출할 수 있도록 도와준다
momentum은 r(감마)은 일반적으로 0.9 또는 비슷한 값이다.
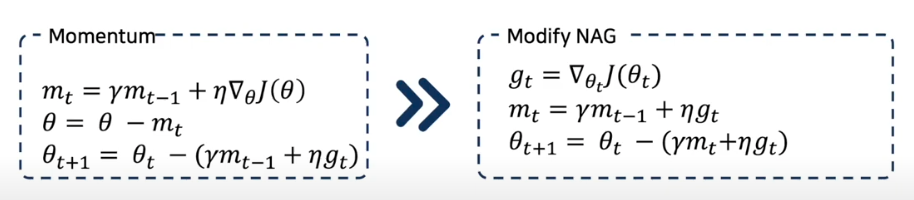
Nesterov accelerated gradient (NAG)
- Global minimum에 도착했으면 멈춰야 하지만 모멘텀 때문에 정확하게 수렴하지 못하게 되는 Momentum 문제점을 해결하기 위해서 만들어진 알고리즘


- 진동을 감소시키고 수렴을 빠르게 만들어 준다
- 일반적으로 기본 모멘텀 최적화보다 훈련 속도가 빠르다
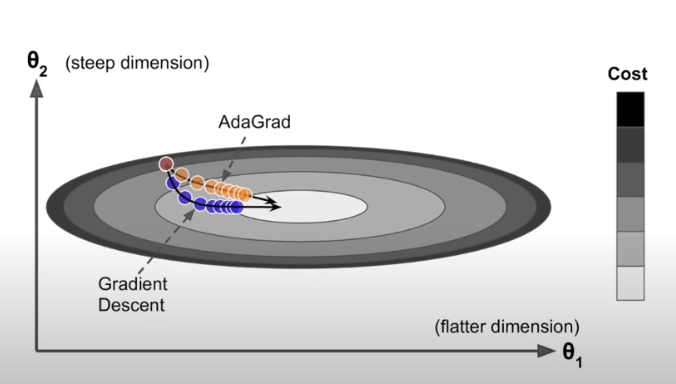
Adagrad (Adaptive Gradient)
안가본 곳은 성큼 빠르게 걸어 훓고 많이 가본 곳은 잘 아니깐 갈수록 보폭을 줄여 세밀히 탐색
SGD 스텝 사이즈 변경
파라미터 마다 lr를 다르게 적용하는 방법
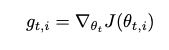
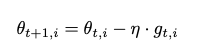
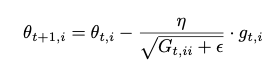
- 빈번하지 않은 parameter에 대해 더 큰 업데이트를 하고, 빈번한 parameter에 대해 더 작은 업데이트를 한다
- 매 단계 t에서 모든 parameter \(\theta_i\)에 대해 다른 learning rate를 사용한다
- 분모에 제곱된 gradient가 누적된다는 것

Adadelta
종종 걸음 너무 작아져서 정지하는 걸 막아보자
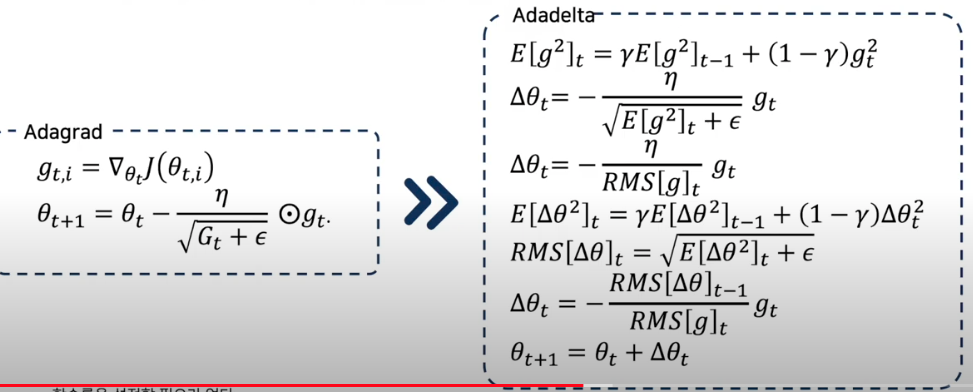
- 과거 제곱 gradient 를 모두 누적하는 대신 누적된 과거 gradient의 창을 고정된 크기 w로 제한
- gradient 합계는 모든 과거 gradient 제곱의 감쇠 평균으로 재귀적으로 정의
RMSprop
보폭을 줄이는 건 좋은데 이전 맥락 상황을 봐가면서 하자

- Adadelta와 RMSprop는 Adagrad의 학습 속도가 급격히 감소하는 문제를 해결해야하기 때문에 거의 동시에 독립적으로 개발
- 학습률을 지수적으로 감소하는 평균 제곱 기울기
- 학습률을 설정할 필요가 없다
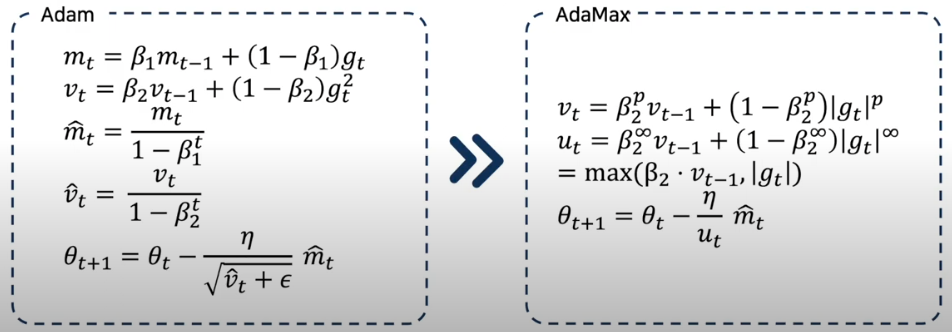
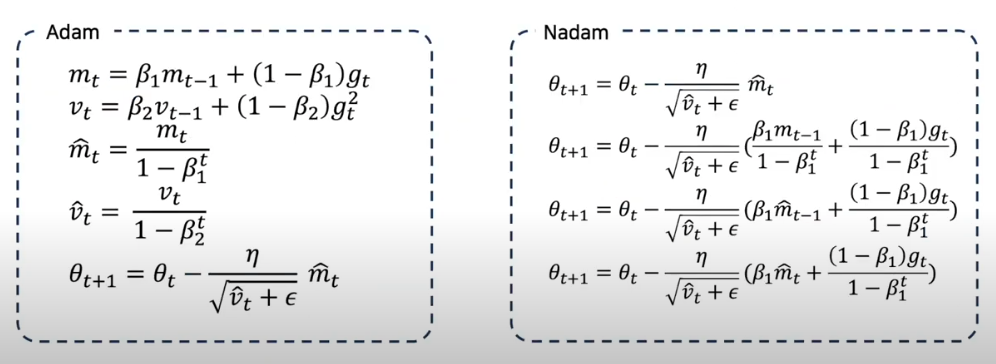
Adam (Adaptive Moment Estimation)
Momentum + RMSprop = Adam
뱡향 및 스텝을 적절히 조절하여 최적화

- 각 매개 변수에 대한 적응 학습률을 계산하는 또 다른 방법
- moment와 유사하게 과거 gradient $m_t$의 지수적으로 감소하는 평균을 유지
- 저자는 $\beta1$에 대해서 0.9
- $\beta1$에 대해서 0.999
- $e$에 대해서 10-8의 기본값을 제안
AdaMax Adam 논문에서 extension으로 제안된 알고리즘
AdaMax는 L2 norm을 기반으로 learning rate를 조절하는 부분을 Lp norm으로 확장시킨 알고리즘
Nadam (Nesterov-accelerated Adaptive Moment Estimation) NAG + Adam = Nadam
⇒ Adam 에 momentum 대신 NAG를 붙이자
⇒ NAG + RMSProp
Visualization of algorithms
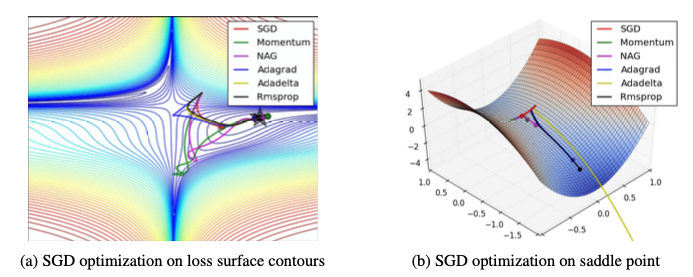
https://cs231n.github.io/neural-networks-3/#sgd
Which optimizer to use?
- Data가 sparse 한 경우 adaptive learning-rate method 사용
- learning rate를 튜닝할 필요도 없고 성능도 좋다
- adagrad의 extension인 RMSprop가 학습 속도가 급격히 작아니는 것을 방지
- RMSporp, Adadelta, Adam 비슷한 결과를 내지만 adam 이 RMSprop보다 최적화가 끝날 때 약간 더 ㅜ띠어난 성능을 발휘한다.
Parallelizing and distributing SGD
Hogwild! cpu에서 sgd 업데이트를 병렬로 수행할 수 있는 기법
각 프로세서가 공유 메모리에 접근해서 파라미터의 일부만 수정하면서 업데이트 하는 방법
Downpour SGD
트레이닝 데이터의 하위 집합에서 모델의 여러 복제본을 병렬로 실행하는 방법
여러 컴퓨터로 분할된 모델들이 파라미터를 다루는 서버에 업데이트를 보내는 방법으로 각 컴퓨터가 파라미터의 일부분을 저장하고 업데이트 하는 방법
Delay-tolerant Algorithms for SGD
비동식 분산 온라인 학습 중 gradient 계산과 해당 업데이트 사이 지연이 생기는 경우 적용할 수 있는 알고리즘
TensorFlow 대규모 기계 학습 모델 구현 및 배포를 위해 구글이 공개한 프레임 워크로 대규모 모바일 장치는 물론 대규모 분산 시스템에서 계산을 수행하는데 사용
Elastic Averaging SGD 비동기식 SGD 로컬 작업자의 파라미터를 파라미터 서버에 저장된 중 파라미터와 연결하여 탄성 평균화를 제안한 방법
Additional strategies for optimizing SGD
Shuffling and Curriculum Learning
Shuffling : Optimization algorithm이 편향되는 것을 막기 위해 모델에 트레이닝 데이터 셋의 순서를 섞는 것
Curriculum learning : 어려운 문제를 해결하고자 하는 경우에는 의미 있는 순서로 데이터를 제공하는 것이 성능이 더 좋을 수 있다
이 의미 있는 순서로 데이터를 제공하는 방법
Batch normalization 학습을 용이하게 하기 위해 parameter의 초기 값을 정규화
하지만 학습이 진행되고 정성화가 없어져 네트워크가 심화됨에 따라 학습 속도가 느려지고 변동 사항이 증폭
이를 해결하기 위해 모든 미니 배치에 대해 정규화를 다시 설정하는 것
Early stopping
학습 진행 중 Validation Error가 더 이상 개선이 되지 않는다 라고 보이면 학습을 중단하는 방법
Gradient noise 각 gradient update에 대해 가우스 분포를 따르는 잡음을 추가하고 다음 스케줄에 따라 분산을 어날링 네트워크가 Initializer에 도움이 되고 심층적이고 복잡한 네트워크를 학습하는데 도움
'Machine-Learning > paper' 카테고리의 다른 글
| [Paper] Faster RCNN (0) | 2022.10.06 |
|---|---|
| [Paper] RCNN (0) | 2022.10.06 |
| [Paper] Attention (0) | 2022.09.15 |
| [CV Paper] Vision Transformer (0) | 2022.08.25 |
| [Paper] Fast RCNN (0) | 2022.08.23 |




댓글