서포트 벡터 머신 (Support Vector Machine, SVM)
- 서포트 벡터 머신은 서포트 벡터를 기준으로 클래스를 판별한다.
- SVM은 퍼셉트론의 확장이라고 생각할 수 있으며, 퍼셉트론 알고리즘을 사용하여 분류 오차를 최소화 한다.
- SVM의 최적화 대상은 마진을 최대화 하는 것이다. 마진은 클래스를 구분하는 초평면(결정 경계)과 이 초평면에 가장 가까운 훈련 샘플 사이의 거리로 정의 된다. 이런 샘플을 서포트 벡터(support vector)라고 한다
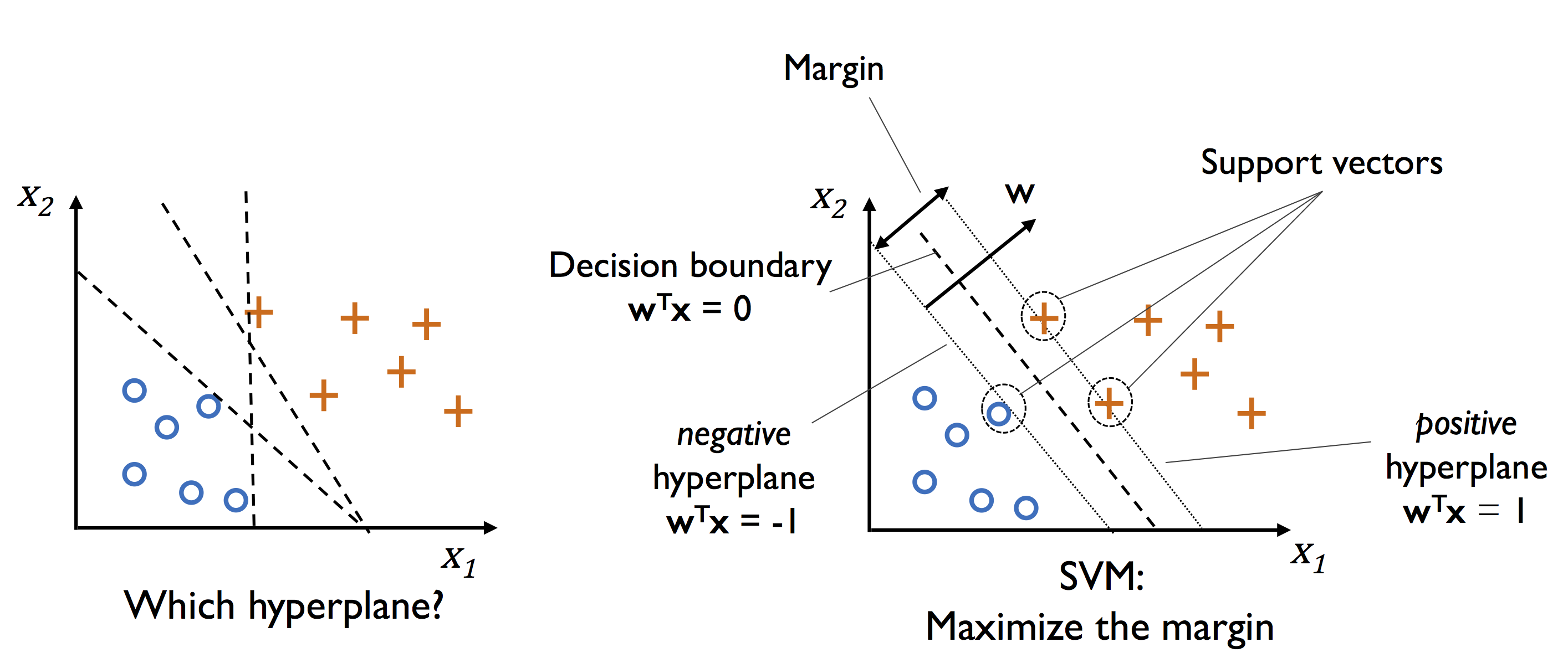
- 최대 마진(large margin)의 결정 경계를 원하는 이유는 일반화 오차가 낮아지는 경향이 있기 대문이다. 반면 작은 마진의 모델은 과대적합되기 쉽다.
소프트 마진 (soft margin)
- 서포트 벡터 머신은 데이터가 잘못 분류되는 경우는 고려하지 않는다. 즉, 트레이닝 데이터로 서포트 벡터 머신을 수행했을 때 서포트 벡터를 기준으로 올바르게 분류되지 않은 영역에 데이터 포인트가 존재하는 경우는 없다는 뜻이다. 하지만 잘못 분류된 데이터가 하나도 없다는 조건은 현실적으로 엄격한 기준이므로 성립도기 어렵다. 소프트 마진(soft margin)은 기존 서프트 벡트 머신의 기준을 완화해 잘못 분류된 데이터를 어느 정도 허용하는 방법이다.
커널 서포트 벡터 머신(Kernel Support Vector Machine)
- 커널 서포트 벡터 머신 이란 피처 공간을 변경한 후 서포트 벡터 머신을 적용하는 것을 의미하는데, 쉽게 말해 좌표 평면을 에로 들면, 뻣뻣한 종이를 기존 공간이라고 생각하고 종이 위에 데이터가 퍼져 였는 상상을 해 본다.
- 이때, 종리를 구부리면 어떻게 될까.? 그러면 기존 좌표 공간에서의 데이터 좌표와 구부러진 공간의 데이터 좌표는 서로 다를 것이다. 구부러진 공간에 대해 서포트 벡터 머신을 적용한 후 종이를 다시 펴면 데이터가 잘 분리된 것을 볼 수 있다. 이때, 서포트 벡터는 비선형이된다.
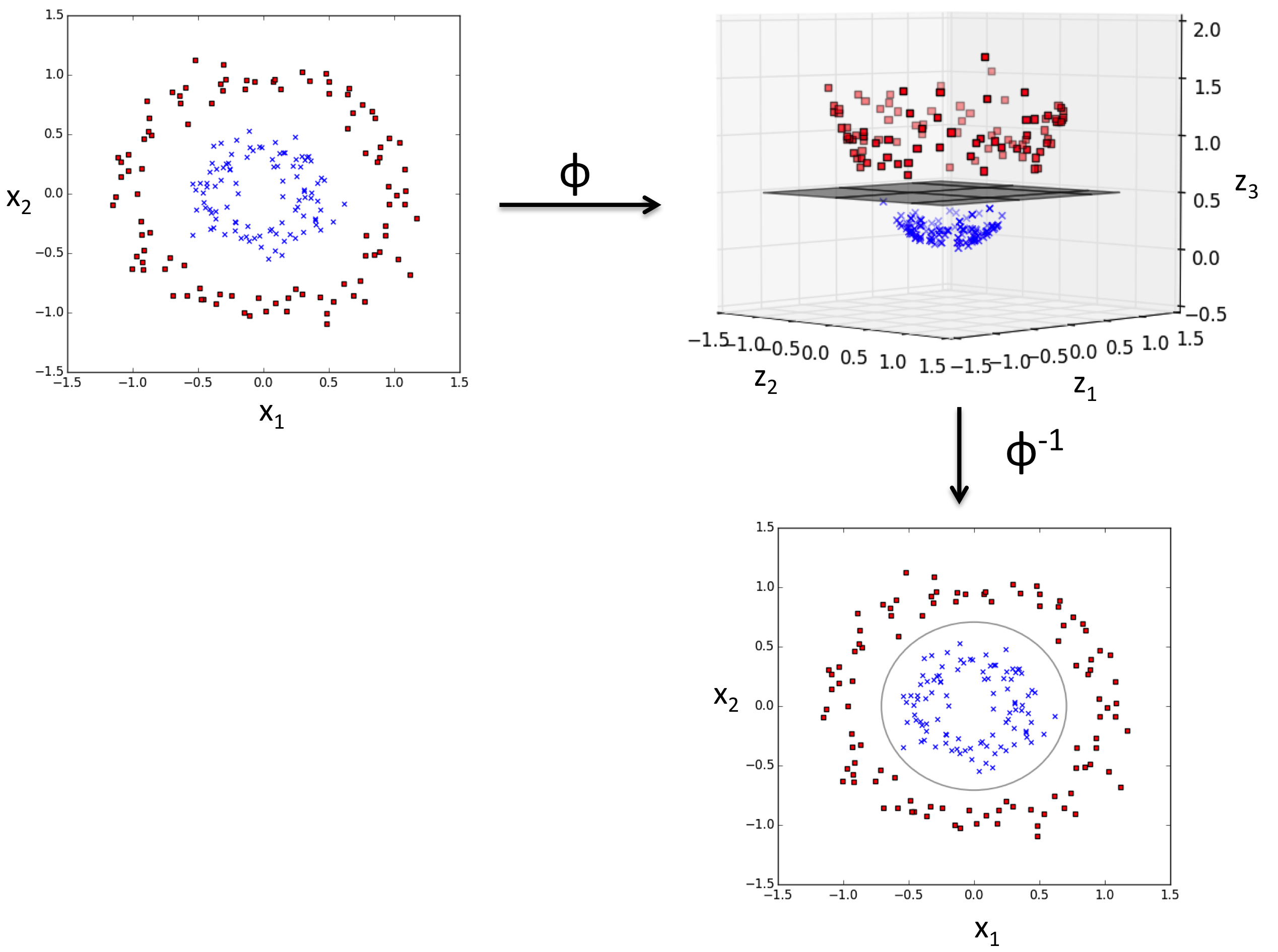
- 두 포인트 사이 점곱을 게산하느데 드는 높은 비용을 절감하기 위한 커널 함수를 정의
- 커널중 가장 널리 사용하는 것은 방사 기저 함수 (Radial Basis Function, RBF), 가우시안 커널이라고 한다
- 커널(kernel)이란 용어의 샘플 간의 유사도 함수 (similarily function)로 해석하할 수 있다. 음수 부호가 거리 측정을 유사도 점수로 바꾸는 역할을 한다. 지수 함수로 얻게 되는 유사도 점수는 1(매우 비슷함 샛플)과 0 (매우 다른 샘플) 사이 범위를 가진다.
# 데이터 불러오기
from sklearn import datasets
raw_wine = datasets.load_wine()
# 피쳐, 타겟 데이터 지정
X = raw_wine.data
y = raw_wine.target
# 트레이닝/테스트 데이터 분할
from sklearn.model_selection import train_test_split
X_tn, X_te, y_tn, y_te=train_test_split(X,y,random_state=0)
# 데이터 표준화
from sklearn.preprocessing import StandardScaler
std_scale = StandardScaler()
std_scale.fit(X_tn)
X_tn_std = std_scale.transform(X_tn)
X_te_std = std_scale.transform(X_te)
# 서포트벡터머신 학습
from sklearn import svm
clf_svm_lr = svm.SVC(kernel='linear', random_state=0)
clf_svm_lr.fit(X_tn_std, y_tn)
SVC(kernel='linear', random_state=0)# 예측
pred_svm = clf_svm_lr.predict(X_te_std)
print(pred_svm)
[0 2 1 0 1 1 0 2 1 1 2 2 0 1 2 1 0 0 1 0 1 0 0 1 1 1 1 1 1 2 0 0 1 0 0 0 2
1 1 2 0 0 1 1 1]
# 정확도
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_te, pred_svm)
print(accuracy)
1.0
# confusion matrix 확인
from sklearn.metrics import confusion_matrix
conf_matrix = confusion_matrix(y_te, pred_svm)
print(conf_matrix)
[[16 0 0]
[ 0 21 0]
[ 0 0 8]]
# 분류 레포트 확인
from sklearn.metrics import classification_report
class_report = classification_report(y_te, pred_svm)
print(class_report)
precision recall f1-score support
0 1.00 1.00 1.00 16
1 1.00 1.00 1.00 21
2 1.00 1.00 1.00 8
accuracy 1.00 45
macro avg 1.00 1.00 1.00 45
weighted avg 1.00 1.00 1.00 45
'Machine-Learning > Basic' 카테고리의 다른 글
| [ML] GirdSearchCV (0) | 2022.11.30 |
|---|---|
| [ML] k-최근접 이웃 (K-Nearest Neighbor) (0) | 2022.11.19 |
| [ML] 활성화 함수 (Activation function) (0) | 2021.09.05 |
| [ML] 손실함수(Loss function) (0) | 2021.09.05 |
| [ML] 경사하강법(Gradient Descent) (0) | 2021.09.05 |

댓글