Mask RCNN
- 별도의 FCN을 ConV Feature Map 다음에 연결해 binary mask 생성
- mask prediction 과 Class predicction의 decouple 정확도 향상
- Faster RCNN과 크게 다르지 않는 구조로써 mask branch, FPN, 그리고 RoI Align 추가
- RPN 전에 FPN (Feature pyramid network)가 추가
- image segmenation 의 masking 위해 RoI align이 RoI Pooling을 대신하게 됐다
Abstract
Mask RCNN은 개념적으로 Object instance Segmentation 을 위한 단순하고, 유연한 일반적인 frame work이다. 이것은 각각의 인스턴스를 위해서 하나의 이미지에 대해서 동시적으로 높은 성능의 segmentation과 효율적인 detect를 발생시킨다. 이 방법을 Mask RCNN이라고 하며 Faster R-CNN을 확장한 것이며, predict해주는 부분에 mask(BBox recognition에 존재하는 곳)에 대해 하나를 추가한 형태이다. 따라서 Faster RCNN에 한가지 부분만 추가해주면 되므로 학습이 간단하다.
또한 Mask R-CNN은 같은 framework 안에서 다른 tasks에도 쉽게 사용할 수 있다. (ex. human poses estimation) 일례로 COCO challenges 우승을 차지하며 모든 tasks (instance segmentation, bounding-box object detection, 그리고 person keypoint detection에서 이전 모델보다 높은 성능을 보였다.
1. Introduction
Mask RCNN 은 Object Detection 및 semantic segmentation를 단시간에 결과에 대해 향상시켰다. 많은 부분에서이들의 각각 Fast/Faster R-CNN는 object detection 그리고 FCN은 semantic segmentation 과 같은 강력한 baseline system을 통해서 진보 되어지고 있다. 기본적으로 instance segmentation을 하기 위한 모델이며, instance segmentation을 하기 위해서는 object detection 과 semantic segmentation 을 동시에 해야 한다. 이를 위해 mask R-CNN 은 기존의 Faster R-CNN을 Object detection 역할을 하도록 하고 각각 RoI에 mask segmentation을 해주는 FCN를 추가해주었다

Faster R-CNN 은 픽셀과 픽셀이 정렬의 과정을 거치지 않게 설계되었다.
기존의 Faster R-CNN은 object detection을 위한 모델이었기 때문에 RoI Pooling 과정에서 정확한 위치 정보를 담는 것은 중요하지 않았다.
RoI Pooling 에서 RoI 가 소수점 좌표를 갖고 있을 경우에서는 각 좌표를 반올림한 다음에 Pooling을 해준다
이렇게 되면 input image의 원본 위치 정보가 왜곡되기 때문에 Classification task 에서는 문제가 발생하지 않지만 정확하게 pixel-by-pixel로 detection 하는 segmentation task 에서는 문제가 발생하며, 이러한 문제인 Misalignment 을 해결하기 위해서 RoI Align 을 사용한다

논문에 수록된 사진을 통해 간단하게 정리하자면 RoI에서 얻어내고자 하는 정보는 박스 안에 동그라미 점입니다. 하지만 이미지 데이터는 정수인 좌표의 값만 갖고 있으므로 화살표로 표현된 방법을 통해 동그라미 점의 값을 구하겠다는 것입니다. 그리고 화살표가 의미하는 방법은 bilinear interpolation (이중 선형 보간법)* 이다

RoIAlign은 mask accuracy에서 큰 향상을 보였다. Mask R-CNN 의 두 번째 힉심은 Mask prediction과 class prediction을 decouple 하였다는 점이다. 이를 통해서 mask prediction에서 다른 클래스를 고려할 필요 없이 binary mask 를 predict 하면 되기 때문에 성능의 향상을 보였다
2. Related Work
- RCNN, - Instance Segmentation
3. Mask R-CNN
- Faster R-CNN : Faster R-CNN은 two Stage 1. RPN 2. Fast R-CNN 기본, cls, reg
Mask R-CNN
- Mask R-CNN은 같은 형태의two stage 절차를 채택했다. 동일한 첫번째 단계 RPN이며, 두번째 단계는 예측하는 Class and Box offset과 평행하게 각각의 binary mask를 예측한다.
- Fearture Extractor (BackBone) : Resnet + FPN (Feature Pyramid Network)
- Totoal Loss = L_cls + L_bbox + L_mask
- Mask Prediction
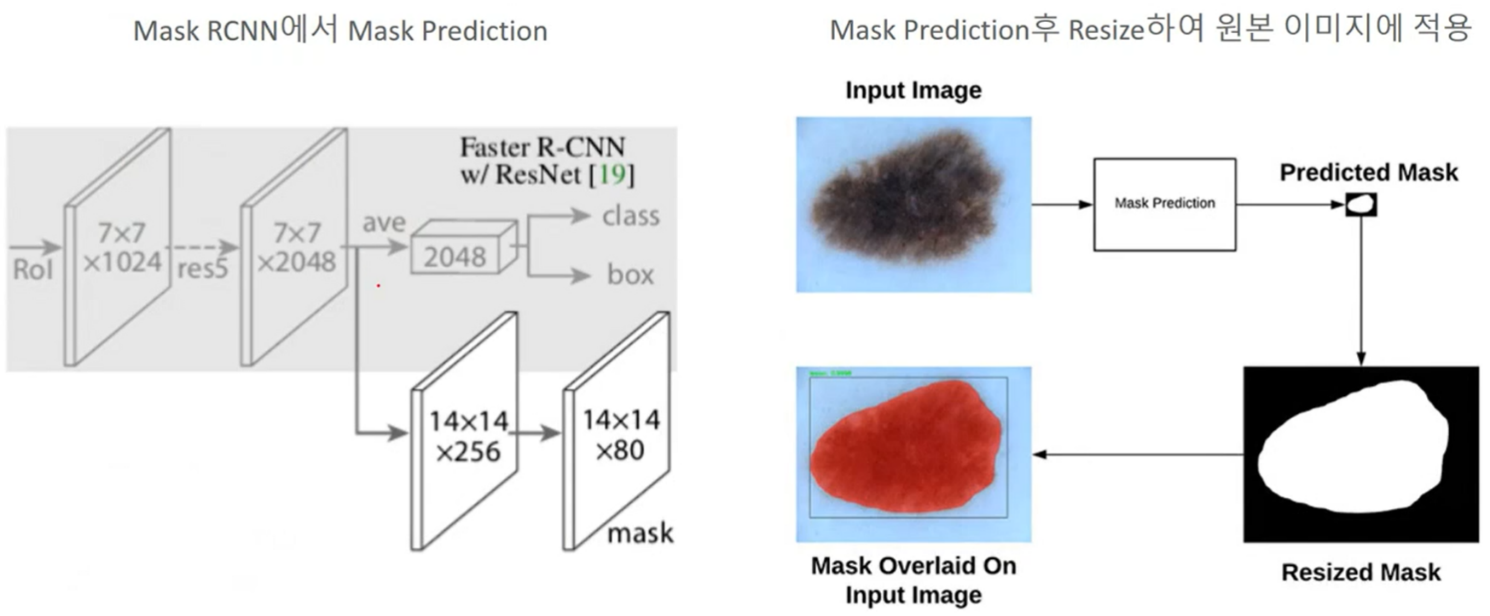
- Mask Representation
: mask는 들어온 물체의 공간적인 형태를 encoding 한다. 그러므로, fc layer로부터 짧은 출력 벡터로 필연적으로 붕괴되어 지는 class labels 또는 box offse와 다르게, conv으로부터 pixel to pixel 로 일치된 것을 마스크의 공간적인 형태로 추출해라.
특별히 FCN(fully convolutional network)을 사용한 각각의 RoI로부터 m x m mask로 예측된다. 이것은 부족한 공간적 치수의 벡터 형태의 붕괴 없이 명백한 m x m 로 유지하기 위한 mask branch안의 각 layer를 허용한다. Mask prediction을 분류를 위한 이전의 방법들인 fc layer와 다르게, 논문에서는 Fully Convolutional representation 은 몇몇의 파라미터가 요구되며, 이것은 실험으로부터 설명을 더욱 정확하게 한다. pixel to pixel 행위는 작은 feature map 을 가지고 있는 RoI feature를 요구되어지며, 픽셀의 공간을 일치를 명확하게 유지 시켜준다.
- Network Architecture
Mask R-CNN은 여러 가지 아키텍쳐를 합친 네트워크인데, 크게 두 가지로 나뉨
(1) Convolutional backbone architecture : 이미지에서 feature extraction
(2) Network head : bounding-box 인식(classification & regression), mask 예측
ResNet Backbone
(2) Head 부분이 Mask R-CNN의 핵심부분이니 아래에서 따로 다루고, 여기서는 backbone에 대해 말해보겠다.
논문에서는 ResNet 과 ResNeXt networks 를 depth 50 or 101 layers에 대해 평가했다.
원래 Faster R-CNN은 ResNet을 사용하는데, 4번째 스테이지의 마지막 Conv layer(이하 C4)에서 features를 뽑아낸다.
이 경우, 이 backbone을 사용한다면 우리는 ResNet-50-C4 와 같이 부를 것이다.
ResNet-50-C4가 일반적이다.
ResNet-FPN Backbone
FPN은 Feature Pyramid Network로, top-down architecture를 사용한다.
FPN backbone을 사용하는 Faster R-CNN은 피쳐 피라미드의 서로 다른 레벨로부터 RoI features를 뽑아내지만, 나머지는 vanilla ResNet과 같다.
Mask R-CNN에서 피쳐 추출을 위해 ResNet-FPN backbone을 이용하는 것은 정확도와 속도 면에서 엄청난 향상을 보였다.
ResNet과 FPN 으로부터 Faster R-CNN box heads를 확장했다. ResNet-C4 backbone의 head는 ResNet의 5번째 stage(이하 'res5')을 포함하는데, 이것은 compute-intensive 하다. FPN에서는, backbone은 이미 res5를 포함하고 있어서 이것은 더 적은 필터를 사용하는 더 효율적인 head를 제공한다.

두 개의 Faster R-CNN head를 확장했다. 왼쪽은 ResNet C4에서 확장한 head, 오른쪽은 FPN backbone에서 확장한 head를 나타낸다. 숫자는 spatial resolution과 채널을 나타낸다. 화살표는 conv, deconv, 또는 fc layers를 나타낸다. 위의 그림은. 헤드 아키텍처 : 기존의 Faster RCNN 헤드 2 개를 확장한다[19, 27]. 왼쪽 / 오른쪽 그림은 mask branch가 추가 된 [19] 및 [27]의 ResNet C4 및 FPN 백본에 대한 헤드를 보여준다.
숫자는 공간 해상도 및 채널을 나타낸다. 화살표는context에서 유추할 수있는 conv, deconv 또는 fc 레이어를 나타낸다(conv는 공간 차원을 유지하고 deconv는이를 증가시킴). 모든 conv는 3x3이며, 출력 conv는 1x1이고 deconv는 2x2이며 strides은 2, hidden layer에는 ReLU [31]가 사용된다.
좌 : 'res5'는 ResNet의 다섯 번째 단계를 나타내며, 단순하게 하기 위해 첫 번째 conv 연산이 7 x 7 RoI / stride 1 ([19]의 14 x 14 / stride 2 대신)에서 작동하도록 변경했다. 우 :‘× 4’는 4 개의 연속된 conv 스택을 나타낸다.
4. Result
5. Mask R-CNN for Human Pose Estimation
- Mask R-CNN의 framework는 human pose estimation으로 쉽게 확장시킬 수 있다. 논문에서는 Keypoint들의 위치를 one-hot mask으로 모델링하며, 각각의 K개의 keypoint type ( left shoulder, right elbow)인 K mask를 예측하기 위해서 Mask R-CNN을 채택했다. 이 일은 Mask R-CNN의 유용성을 설명하는데 도움을 준다
논문에서는 human pose의 최소한의 도메인 지식을 가지고도 우리의 시스템을 이용할 수 있다고 언급한다. 이 실험은 Mask R-CNN 의 일반론을 입증하기 위한 것처럼 .. (이하 생략)
Implementation Detail
: 논문에서는 keypoint와 같은 것을 채택하기 위해서 segmentation 시스템을 최소한의 수정으로 만들었다. Instance의 K keypoints에 대한 각각, 그 훈련 목표는 단지 중요한 위치(foreground)로서 라벨링 되어있는 single pixel에 대해서 one-hot m x m binary mask하기 위함이다. 훈련 도중에는, 논문에서는 존재하는 각각의 ground-truth keypoint에서 single point 를 탐지하는 m^2-way softmax output이 cross-entropy loss가 최소화 한다.
논문에서는 instance segmentation 처럼 K keypoint 를 아직도 독립적으로 다룬다.
논문에서는 ResNet-FPN 을 채택했고, keypoint head architecture 는 4. Right 유사하다. keypoint head는 deconv layer and 2x bilinear upscaling 따르는 8개의 3x3 512–d conv layers를 구성하고, 56 x 56 output 생산한다. 논문에서는 keypoint-level 위치 정확도가 요구되는 상대적으로 높은 resolution output (mask와 비교하여) 발견되었다
Model은 어노테이트된 keypoint를 포함하는 coco trainval 35k 이미지 모두를 학습시켰다. 오버피팅을 줄이기 위해서 training set은 작게 하였고, 논문에서는 scales 램덤하게 [640, 800] pixel을 사용하였다. Inference는 800pixel 의 single scale 로 하였다.
Interations 90k 으로 학습,
Learning rage 0.02 (10을 줄일때마다) : 60k and 80k interations .
Bbox NMS Threshold 0.5
(NMS( non-maximum suppression)
: object detection 알고리즘을 구성하는데 대부분 NMS 을 사용하여 연산량을 줄이고 mAP 도 올리는 효과를 본다. 일반적으로 영상에지를 찾기 위한 NMS 는 현재 픽셀을 기준으로 주변의 픽셀과 비교했을 때 최대값을 경우 그대로 놔두고 아닐경우 (비 최대) 억제(제거)하는 것이다
딥러닝을 이용한 object detection에서 대부분은 bounding box + 각 box에 object 가 있을 확률 (class 확률)들이 나오게 되는데, 이중 겹치는 부분을 제거하기 위한 방법으로 사용된다.
NMS를 하려는 가장 큰 이유는 역시 중복제거이기 대문에 예측하 박스들 중 IOU가 일정이상인 것들에 대해서 수행하게 된다.)
'Machine-Learning > paper' 카테고리의 다른 글
| [Paper] GPT (Generative Pre-trained Transformer) (0) | 2022.12.28 |
|---|---|
| [Paper] CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features (0) | 2022.10.17 |
| [Paper] Faster RCNN (0) | 2022.10.06 |
| [Paper] RCNN (0) | 2022.10.06 |
| [Paper] Attention (0) | 2022.09.15 |




댓글