GPT (Generative Pre-Training of a Language Model)
https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
As of 24 February 2020, Three are 6,020, 081 article in the English Wikipedia containing over 3.5 billion words
즉, labeling된 데이터보다 unlabeling 된 데이터의 수가 훨씬 더 많다는 것을 알 수 있다.
그런데, 이 labeling된 데이터셋보다 훨씬 더 많은 unlabeling된 데이터 셋을 잘 활용하면 더 좋은 supervised laerning에 대해서도 훨 씬 더 좋은 퍼포먼스를 낼 수 있을 것이다라는 아이디어로 시작하였다.
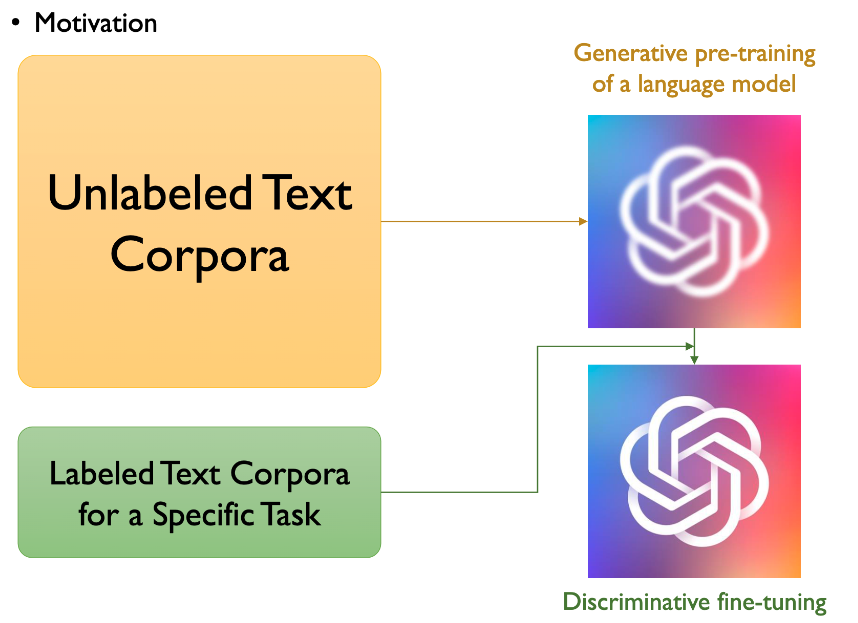
위의 그림에서 알 수 있듯이, 먼저 Unlabeled Text Corpora를 이용해서 GPT를 통해 학습하여 임베딩을 만든다. 다음으로는 labeled text corpora for specific task에 대해서 fune-tuning을 하게 되면 우리가 훨씬 더 좋은 성능을 낼 수 있을 것이라는 아이디어에서 시작하였다. 이는 ELMO와 유사하게 진행되는 걸 알 수 있다
GPT에서 제시하는 문제점

워드 레벨 이상의 어떤 정보를 사용하는 것은 레이블이 되지 않는 텍스트 데이터로부터 단어 레벨 이상의 어떤 정보를 사용하는 것보다 광징히 도전적이다. 왜냐하면 단순히 레이블이 되지 않은 텍스트만을 가지고서는 어떠한 optimization objectives 가 효율적인가에 대해서는 사실을 잘 모르기 때문이다.
실제로 이게 학습이 되었다고 할지라도 target task (ex. 분류, 번역 등)가 주어졌을 때 어떤 방식으로 변형 (transfer)하는게 효율적인지에 대해서는 잘 모른다.
ELMO와 GPT의 차이점
EMLO와 GPT의 차이점을 설명하면, 위의 그림에서 볼 수 있듯이 엘모는 주어진 시퀀스가 주어져 있으면 forward와 backward를 모두 사용해서 선형 결합을 이용하여 최종적으로 결과를 예측하게 된다. 하지만 GPT의 경우 transforemr 의 Decoder 부분만을 사용한다. 또한 Backword를 사용하지 않고 forward에 대해서도 making을 한거에 사용한다. 즉 디코딩 block 쪽만 최종적을 예측하게 된다.

Unsupervised pre-training

여기서 최종 목적은 i에 대한 모든 시퀀스에 대해서, 바로 전 단계에서부터 k번째 이전까지 살펴본 다음에 i번째에 해당하는 토큰 또는 단어가 무엇인지에 대한 likelihood를 최대한 시키는게 목적이다.
여기서 k는 context window의 크기를 의미하며, p는 신경망 파라미터를 사용한 조건부 확률을 의미한다.

GPT의 구조를 살펴보면 GPT의 경우는 multi-layer Transforemr의 디코더 부분을 사용한다. 결국 Transformer의 인코더와 디코더 부분이 있다면, 인코더에 있는 제외 하였다. 그래서 인코더 부분에 있었던 각 attention을 사용하지 않고, 디코더 부분의 Masked Multi-head Attention 부분을 사용해서 여러개를 위로 쌓는다. 이렇게 디코더 부분만이 위로 쌓아서 만든 것을 GPT라고 할 수 있다.

위의 그림은 정보가 주어졌을 때 해당하는 토큰의 바로 이전 것을 까지만 사용하는 Masked Self-Attention을 사용한다. 아래 왼쪽 그림에서 볼 수 있듯이 self-attention은 주어진 토큰 모두 사용하는 반면에, 오른쪽 Masked self-attention은 주어진 까지 사용하는 것이 차이점이라고 할 수 있다. 즉, 첫 프로세싱하고자 하는 토큰 다음 시퀀스에 것들은 사용하지 않는 것을 의미한다.
또한, Transformer에서는 Masked self-attention 다음으로 encoder-decoder self-attention을 사용하지만, GPT에서는 encoder-decoder self-attention을 사용하지 않는다.
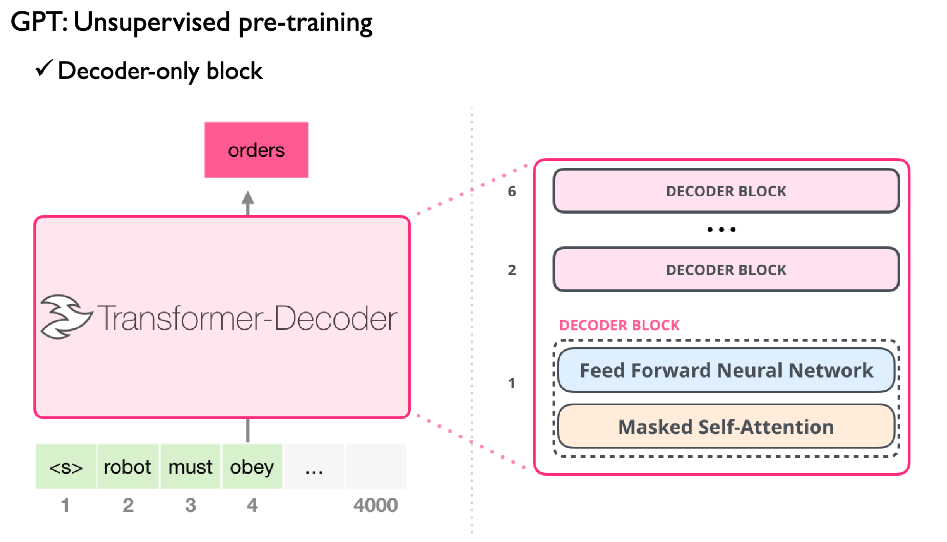
즉, GPT는 Decoder 부분은 Masked Self-attention 이후 Feed Forward Neural Network로 바로 진행한다. (여기서 Add & Norm (residual block은 당연히 진행한 것으로 가정)
Supervised fine-tuning

L2(C) supervised learning 목적 함수는 최종적으로 label y 가 있을 때 주어져 있는 토큰 시퀀스 값들 수에 따라서 정답 (y)이 무엇인가에 대해서 확률에 대한 최대값을 구하게 되는 것이다.
ELMO 의 경우 language 모델을 먼저 만들고 히든 스테이트 벡터 들을 고정시킨 상태에서 가중치만을 down stream에 적절한 워드 벡터들을 찾아 낸다

L1 language 모델에 대한 목적 함수
L1(U)의 경우 ublabeled 된 데이터 셋을 이용하여 pre-training을 한 후에 C는 supervised learning에 해당하는 목적 함수이며 L1는 L1(U)의 경우 unlabeled 된 데이터 셋을 이용하여 pre-training을 함께 학습하며 다음과 같은 장점을 가질 수 있다.
- supervised 모델의 Generalization 향상시키며
- Convergence의 속도가 향상된다.
task 에 따른 비교
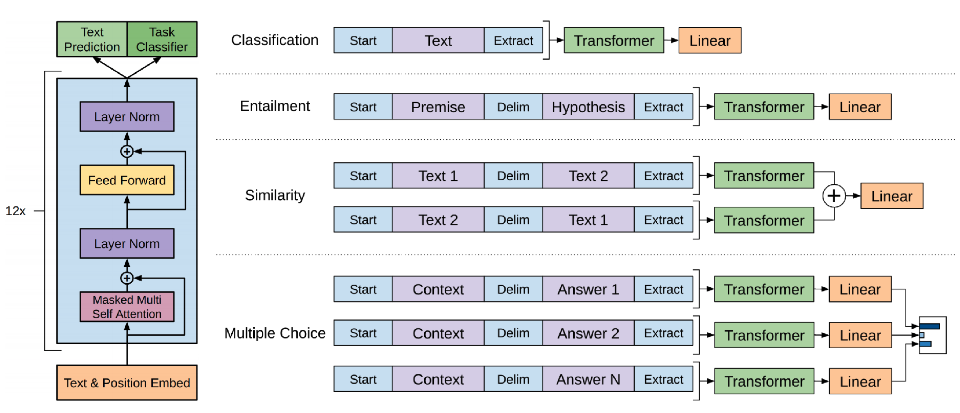

위의 Task는 4가지로 구분할 수 있으며, 각 Task에 따라서 해당 Transformer의 사용 갯수와, 사용한 문장들의 수가 달라지는 것을 볼 수 있다. Multiple Choice의 경우 해당 Context 와 AnswerN에 대한 Transformer에 대한 Linear를 구한 후 마지막에 각각의 Linear에 대한 softmax를 통해 output을 얻는다.
Experiments
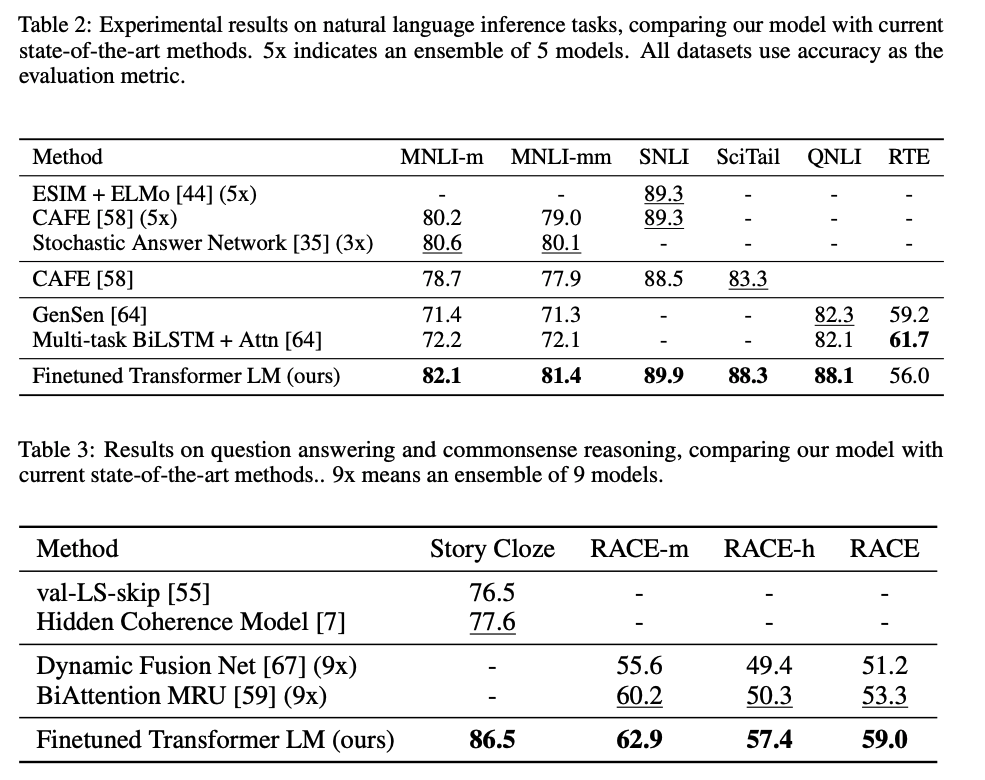
GPT는 Finetuned Transformer LM이라는 결과로 보여지며 몇개의 Dataset에 대해서는 제외하고 좋은 성능을 보였다.
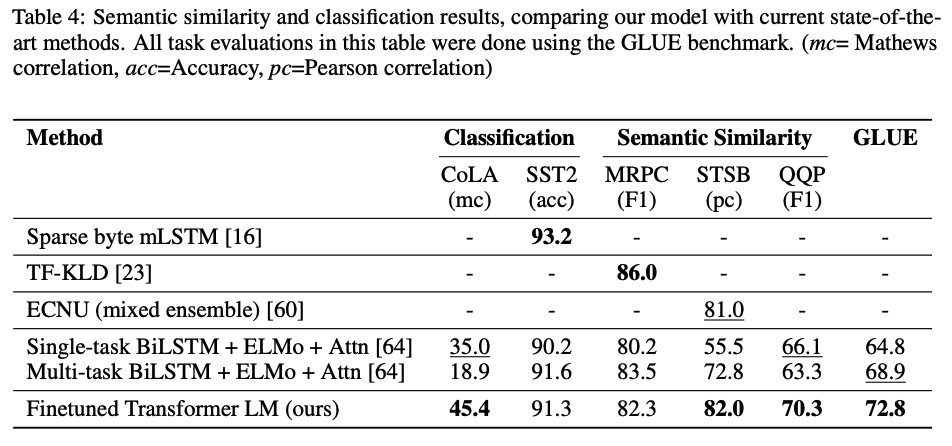
Analysis
Impack of number of layered transferred and Zero-shot behaviors
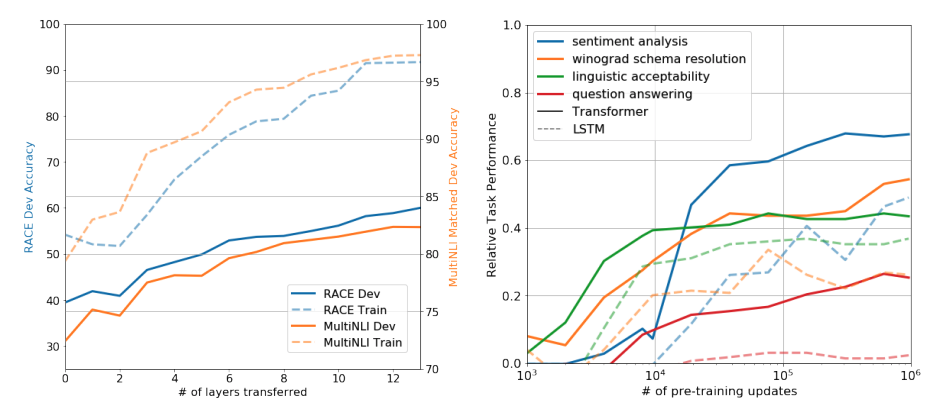
왼쪽의 그래프는 디코더 블럭을 몇개를 쌓았는지 대한 결과를 보여지고 있으며, 오른쪽 그래프는 unsupervised learning을 통해 만든 다음에 zero-shot을 이용해서 업데이트 했을 때와 fine-tuning 파라미터의 업데이트 했을 때 결과를 보여지고 있다.
왼쪽은 최대 12개의 블럭을 쌓은 결과를 보여지며 블락이 많이 질 수록 성능이 올라가는 것을 볼 수 있으며, 오른 쪽은 unsupervised learning을 통해 얻은 결과로 업데이한 결과에 대해서 fine-tuning을 할 수록 결과가 좋아지는 것을 볼 수 있다.
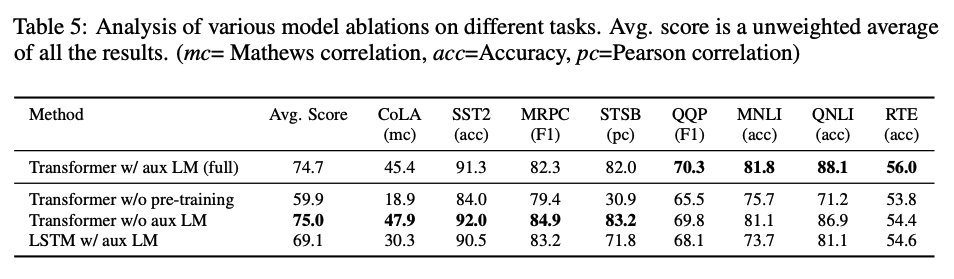
Reference
고려대 강필성 교수님 강의 : https://www.youtube.com/watch?v=o_Wl29aW5XM
'Machine-Learning > paper' 카테고리의 다른 글
| [paper] Mask RCNN (0) | 2022.11.24 |
|---|---|
| [Paper] CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features (0) | 2022.10.17 |
| [Paper] Faster RCNN (0) | 2022.10.06 |
| [Paper] RCNN (0) | 2022.10.06 |
| [Paper] Attention (0) | 2022.09.15 |




댓글