RNN (Recurrent Netural Network, 순환신경망)
RNN (Recurrent Netural Network, 순환신경망)은 NLP 처리 분야에서 뿌리가 될 만큰 중요한 것이다. NLP 분야에서 단어들이 모여 문장이 되고, 문장이 모여 문서가 되는 듯이 문장 내 단어들은 앞뒤 위치에 따라 서로 영향을 주고 받는다. 문서 내 문장들도 마찬가지다.
따라서 단순히 \(y = f(x)\)와 같은, 순서의 개념 없이 입력을 넣으면 출력이 되는 함수가 형태가 아닌, 순차적(Sequential)으로 입력을 넣고, 입력에 따라 모델의 은닉 상태 (Hidden State)가 순차적으로 변하며, 상태에 따라 출력 결과가 순차적으로 변환되는 함수가 필요했다.
이러한 시간 개념 또는 순서 정보를 사용하여 입력을 학습하는 것을 시퀀셜 모델링 (Sequential modeling)이라고 한다. 이 부분에서는 순환 신견망(RNN)이라는 것을 통해 효과적으로 문제를 해결할 수 있다.
이처럼 RNN은 시퀀스 데이터를 모델링하기 위해 등장했으며, 기존의 뉴럴 네트워크와 다른 점은 기억 (hidden state)을 갖고 있다는 점이다. 기존의 신경망 구조에서는 모든 입력이 각각 독립적이라고 가정했는데, 많은 경우에 이런 방법은 옮지 않을 수 있다. 예를 들어, 문장에서 다음에 나올 단어를 추측하고 싶다면 이전에 나온 단어들의 연속성은 아는 것 자체가 큰 도움이 될 수 있다.
RNN이 Recurrent하다고 불리는 이유는 동일한 태스크를 한 시퀀스의 모든 요소마다 적용하고, 출력 결과는 이전의 계산 결과에 영향을 받기 때문이다.
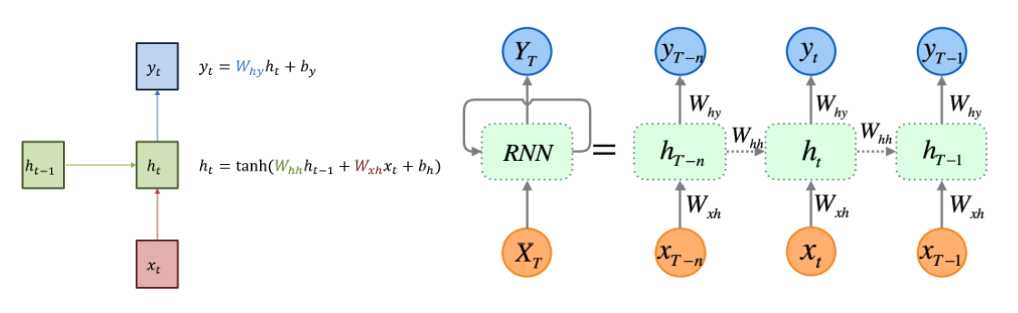
RNN의 기본 구조는 위의 그림과 같다. 빨간색 부분의 입력 \(x_t\)에서 녹색 부분의 hidden state \(h_t\) 그리고 파란색 부분의 출력 \(y_t\)로 이어지고 있다. 이때 녹색 부분의 hidden state \(h_t\) 는 직전 시점의 hidden state \(h_{t-1}\) 을 받아 업데이트 한다
hidden state에서 활성화 함수(activation function)를 통해 결과를 내보내는 역할을 하는 노드를 셀(cell)이라고 한다. 이 셀은 이전의 값을 기억하려고 하는 일종의 메모리 역할을 수행하므로 이를 메모리 셀 또는 RNN 셀이라고 표현한다.
또한 hidden state의 메모리 셀은 각각이 시점 (time step)에서 바로 이전 시점에서의 hidden state 메모리 셀에서 나온 값을 자신의 입력으로 사용하는 재귀적활동을 한다. 메모리 셀이 출력층 방향으로 또는 다음 시점의 자신에게 보내는 값을 은닉상태(hidden state)라고 한다.
위의 그림에서 알 수 있듯이 활성화 함수는 비선형 함수인 하이퍼볼릭탄젠트(tanh)이다.
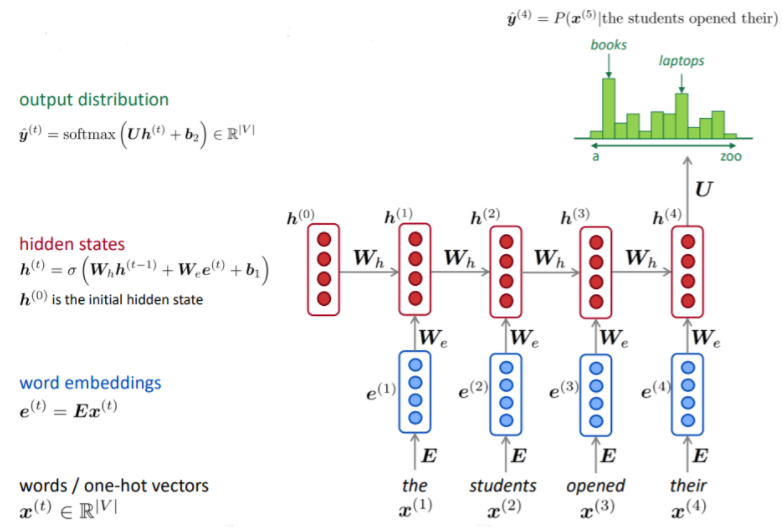
RNN의 구조의 흐름을 자세히 그림으로 표현한 것의 위의 그림이다. 해당 그림을 조금 구체적인 예시로 표현해보자

one-hot vector로 표현된 t 시점의 하나의 단어 (word)를 \(x^{(t)} \in \mathbb{R^{\left|V \right|}}\)라고 표현할 수 있을 것이다.
이때 V는 vacabulary size 이며, \(x^{(t)}\) = \(\begin{bmatrix} 0 & 0 & ... & 1 & 0 & 0 \\ \end{bmatrix}^{T} \) 이며, 해당 단어들에 들이 갯수는 V와 동일하다. 위 그림으로 표현하자면 the, students, opened, their로 4개가 될 것이다.

해당 그림은 각 word들을 embedding한 것으로 \(e^{(t)}\)라고 표현한다. 즉 임베딩 함수를 \(E\)로 표현하여 각 단어 \(x^{(t)}\)에 적용한 것을 \(e^{(t)} = Ex^{(t)}\) 으로 표현할 수 있다.

위의 그림은 hidden state \(h^{(t)}\)는 이전 hidden state \(h_{t-1}\) 와 현재 word embedding \(e^{(t)}\) 의 bias를 포함한 선형 결합에 활성화 함수 \(\sigma \) 를 결합한 벡터라고 할 수 있다.
$$ h^{(t)} = \sigma(W_{h}h_{t-1} + W_{e}e_{t} + b_h) $$
이때, 각 입력과 출력 그리고 내부 파라미터 크기는 다음과 같다
$$ h_t \in \mathbb{R}^4,\; W_h \in \mathbb{R}^{4x4},\; h_{t-1} \in \mathbb{R}^4,\; W_e \in \mathbb{R}^{4x4},\; e_{t} \in \mathbb{R}^4,\; b_{1} \in \mathbb{R}^4 $$

$$ \hat{y}^{(t)} = softmax(Uh^{(t)} + b_2) \in \mathbb{R}^{|V|} $$
해당, \( \hat{y}^{(4)} = P(x^{5}|the\; students \; opend \; their) \)
식에 따라 예측 단어 \(\hat{y}^{(4)} \)는 the students opened their의 나올 값을 구하는 것이므로, 그 실제 이전 값들의 hidden state를 이용하여 마지막인 hidden state \(h^{(4)}\)를 이용하여 예측 단어를 찾을 수 있다
이때, 각 입력과 출력 그리고 내부 파라미터 크기는 다음과 같다
$$ \hat{y}^{(4)} \in \mathbb{R}^{|V|},\; U \in \mathbb{R}^{|V|x4},\; h_{t} \in \mathbb{R}^4,\; b_1 \in \mathbb{R}^{|V|} $$
'Machine-Learning > NLP (Natural Language Processing)' 카테고리의 다른 글
| [NLP] Transformer-Overview (0) | 2022.10.11 |
|---|---|
| [NLP] Seq2Seq (0) | 2022.10.04 |
| [NLP] LSTM /GRU (0) | 2022.09.29 |
| [NLP] 셀프 어텐션의 작동 원리 (0) | 2022.09.26 |
| [NLP] NLP의 이해 (0) | 2022.09.26 |




댓글