LSTM (Long Short-Term Memory)
RNN은 가변 길이의 시퀀셜 데이터 형태 입력에는 훌륭하게 동작하지만, 그 길이가 길어지면 앞서 입력된 데이터를 잊어버리는 단점을 가지고 있다. 하지만 LSTM의 등작으로 RNN을 단점을 보완할 수 있게 되었다.
LSTM은 기존 RNN의 은닉 상태 이외에도 별도의 셀 스테이트 (cell state)라는 변수를 두어 그 기억력을 증가 시킨다. 그 뿐만 아니라 여러 가지 게이트(gate)를 둠으로써 기억하거나, 잊어버리거나, 출력하고자 하는 데이터의 양을 상황에 따라 마치 수도꼭지를 잠갔다가 열듯이 효과적으로 제어한다. 그 결과 긴 길이의 데이터에 대해서도 효율적으로 대처할 수 있게 되었다

요약하면 장단기 메모리(Long Short-Term Memory), LSTM은 은닉 층(hidden state)의 메모리 셀에 입력 게이트(input gate layer ), 망각 게이트(forget gate Layer ), 출력 게이트(output gate layer )를 추가하여 불필요한 기억을 지우고, 기억해야할 것들을 정한다.
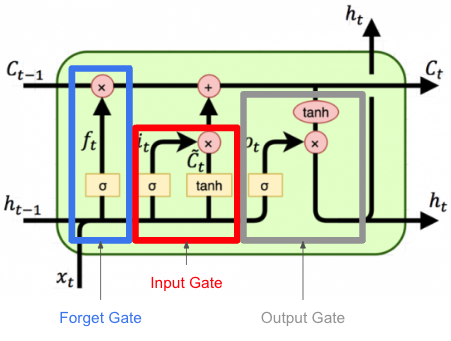
LSTM의 핵심은 다이어그램 상단을 가로지르는 수평선의 셀 상태이다.
셀 상태는 일종의 컨베이어 밸트와 같다. 약간의 선형 상호 작용만 포함하여 전체 체인을 따라 실행된다.

LSTM은 게이트라고 하는 구조에 의해서 셀 상태에 정보를 제거하거나 추가할 수 있는 기능이 있다.
각 게이트 앞에는 시그모이드(Sigmoid\((\sigma)\)가 붙어 0에서 1사이의 값으로 얼마나 게이트를 열고 닫을지를 결정한다.
게이트는 x에 의해 결정되고, 또 다른 x의 함수에 곱해지므로 결과적으로 x에 관한 서로 다른 함수의 곱 형태가 된다. 그럼 미분에 기울기를 전달하기 좋은 형태가 되어 기울기 소실 문제가 해결되는 장점을 가지고 있다.
그럼 그 결정된 값에 따라서 셀 스테이트 \(c_{t-1}\)와 \(g_{t}\), \(c_{t}\) 가 새롭게 인코딩 된다.
LSTM 단계별 구조
forget gate Layer
- 과거의 정보를 버릴지 말지를 결정하는 게이트
- sigmoid 활성화 함수를 통해 0 ~ 1 사이의 값을 출력

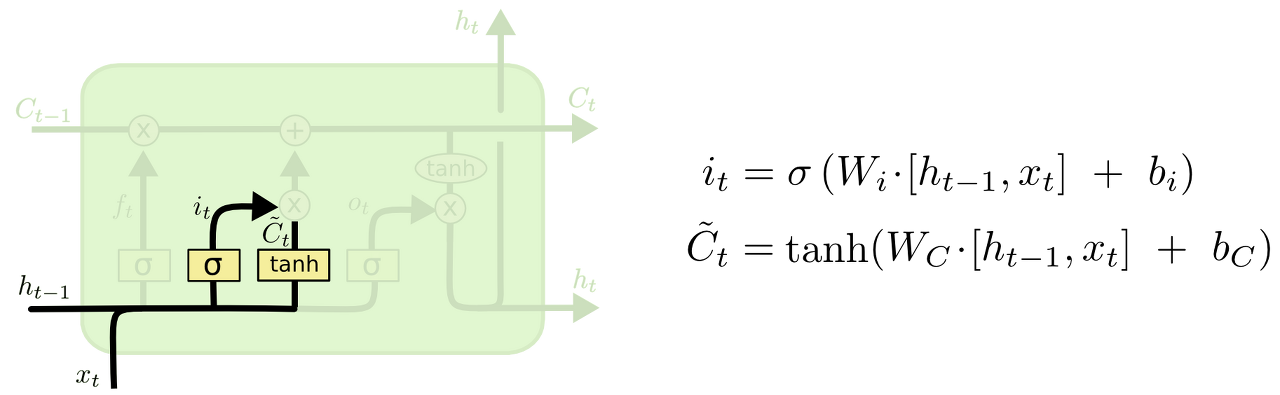
input gate layer
- 새로운 정보가 cell state에 저장이 될지 결정하는 게이트
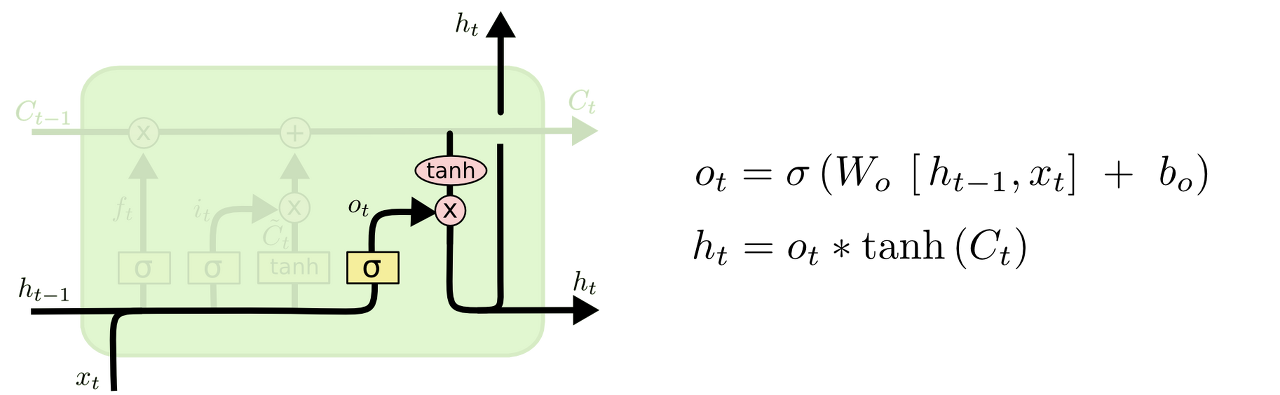
output gate layer
- 상태를 바탕으로 시그모이드 층에 input 데이터를 태워 상태의 어느 부분을 출력을 내보낼지 결정하는 게이트
update cell state
- forget gate와 input gate에서 출력된 값들을 cell state로 업데이트

GRU (Gate Recurrent Unit)
GRU(Gate Recurrent Unit) 는 LSTM의 간소화 버전이다. 기존 LSTM이 복잡함 모델인 데 비해 더 간단하면서 성능이 비슷한 것이 특징이다.

GRU 또한 LSTM과 마찬가지로 시그모이드 \(\sigma\)로 구성된 리셋 게이트 (reset gate) \( r_t\)와 업데이트 게이트 (update gate) \(z_t\)가 있다. 마찬가지로 시그모이드 함수로 인해 게이트의 출력값은 0과 1 사이로 나오므로, 데이터의 흐름을 게이트를 열고 닫아 제어할 수 있다. 기존 LSTM 대비 게이트 숫자가 줄어들게 되고, 따라서 게이트에 딸려있던 파라미터도 그만큼 줄어들어 계산을 줄인다
GRU는 LSTM 대비 더 가벼운 몸집을 자랑하지만, 아직까지는 LSTM을 사용하는 빈도가 더 높다. 특별히 성능의 차이가 있다기보다는 LSTM과 GRU의 학습률이나 은닉 상태의 크기 (hidden size)등의 하이퍼파라미터가 다르다. 따라서 사용 모델에 따라 파라미터 셋팅을 다 찾아내야 한다.

참고 자료
1. 한국어 임베딩 도서
2. 딥러닝을 이용한 자연어 처리 입문 : https://wikidocs.net/22888
3. 김기현의 자연어 처리 딥러닝 캠프
4. http://colah.github.io/posts/2015-08-Understanding-LSTMs/
'Machine-Learning > NLP (Natural Language Processing)' 카테고리의 다른 글
| [NLP] Transformer-Overview (0) | 2022.10.11 |
|---|---|
| [NLP] Seq2Seq (0) | 2022.10.04 |
| [NLP] RNN (Recurrent Netural Network) (0) | 2022.09.29 |
| [NLP] 셀프 어텐션의 작동 원리 (0) | 2022.09.26 |
| [NLP] NLP의 이해 (0) | 2022.09.26 |




댓글