트랜스포머 디코더 이해
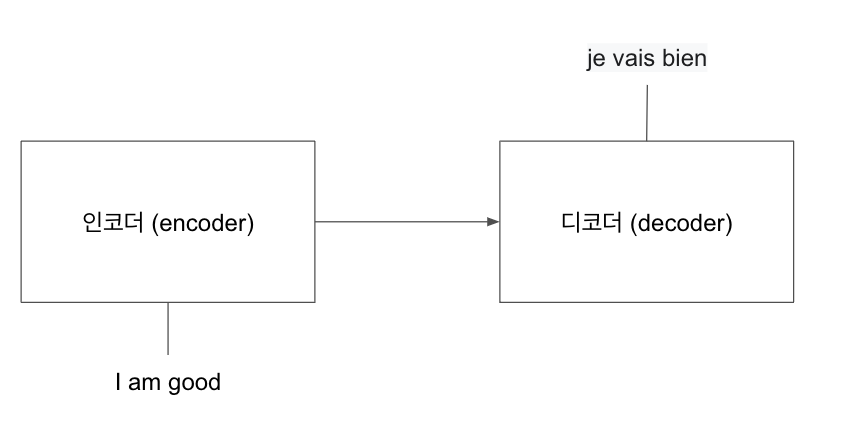
영어 (입력 문장) 'I am good'을 입력하면 프랑스어 (타킷 문장) 'je vais bien'을 생성하는 번역기를 만든다고 가정하자. 번역기를 만들려면 먼저 입력 문장인 'I am good'을 인코더에 입력해야 한다. 인코더는 임력 문장의 표현 학습한다.
인코더의 입력 결과값을 가져와서 디코더에 입력값으로 사용하며, 디코더는 다음과 같은 그림으로 인코더의 표현을 입력값으로 사용하고 타깃 문장인 'je vais bien' 을 생성한다.
인코더 부분을 다룰 때 인코더 N개를 누적해서 쌓을 수 있다는 것을 배웠다.
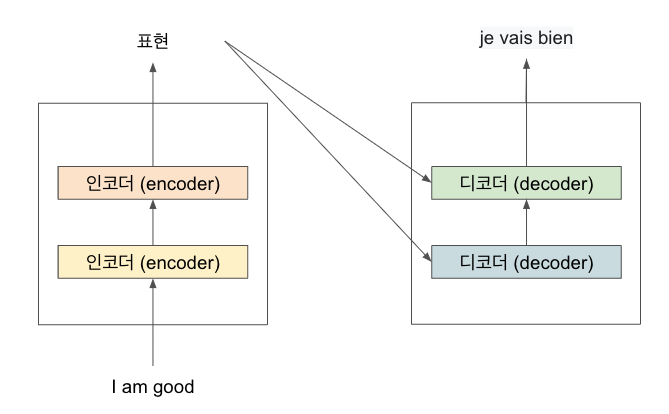
인코더와 유사하게 디코더 역시 N개를 누적해서 쌓을 수 있다. N=2로 예를 들어보면
표시된 것처럼 하나의 디코더 출력 값은 그 위에 있는 디코더의 입력 값으로 전송된다. 또한 인코더의 입력 문장 표현 (인코더의 출력 값)이 모든 디코더에 전송되는 것을 알 수 있다. 즉, 디코더는 이전 디코더의 입력값과 인코더의 표현 (인코더의 출력값), 이렇게 2개를 입력 데이터로 받는다
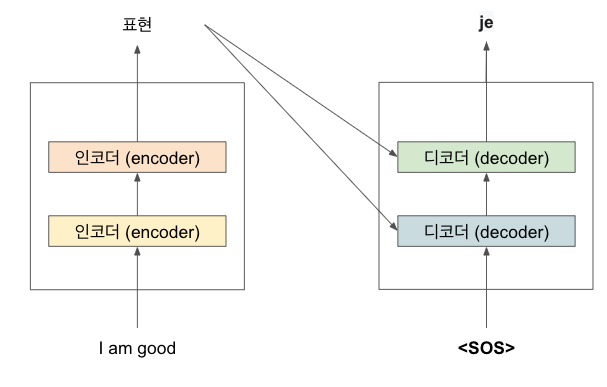
그렇다면 디코더는 사용자가 원하는 문장을 어떻게 생성할까? 이에 대해 좀 더 자세히 알아보자. 시간 스텝 t=1이라면 디코더의 입력 값은 문장의 시작을 알리는 <sos>를 입력한다. 이 입력값을 받은 디코더는 타깃 문장의 첫 번째 단어인 'Je'를 생성한다
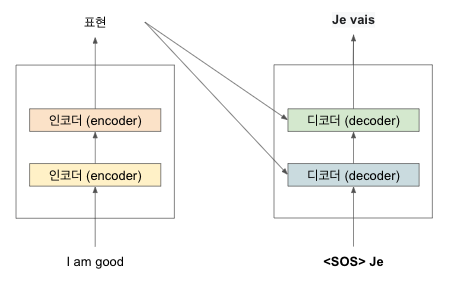
시간 스템 t=2 경우 현재까지의 입력 값에 이전 단계 (t-1) 디코더에서 생성한 단어를 추가해 문장의 다음 단어를 생성한다.
디코더는 <sos>와 'Je' (이전 단계의 생성 결과)를 입력받아 타킷 문장의 다음 단어를 생성한다
시간 스탭 t=3의 경우 역시 이전 단계와 동일한 방법으로 진행한다. 이때 디코더의 입력은 <sos>, 'Je', 'vais'이고 이 입력값을 활용해 다음 단어를 생성한다.
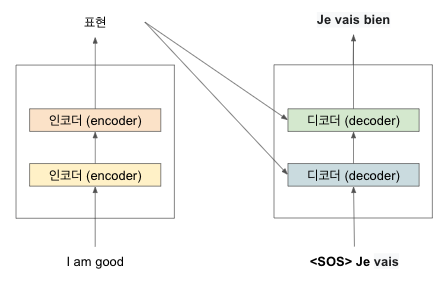
위의 방법과 마찬가지로 모든 단계에서 디코더는 이전 단계에서 새로 생성한 단어를 조합해 입력 값을 생성하고 이를 이용해 다음 단어를 예측하는 방법을 진행한다. 따라서 t=4의 경우 <sps> 'Je', 'vais', 'bien'을 입력하고 다음 단어를 예측한다
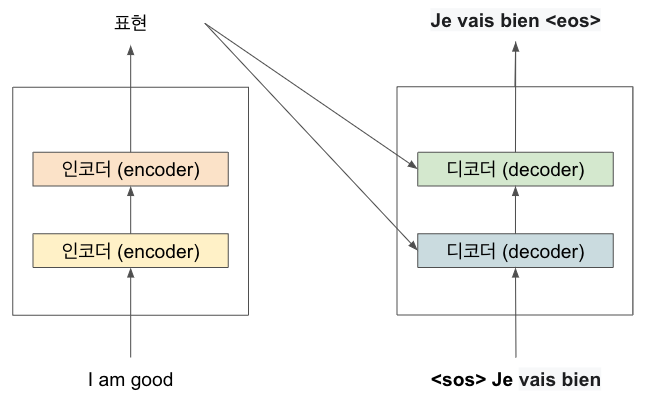
위의 그림을 통해 알 수 있듯이 디코더에서 <eos> 토큰을 생성할 때 카깃 문장의 생성이 완료된다.
인코더의 경우, 입력 문장을 입력 문장을 임베딩 행렬로 변환한 후 여기에 위치 인코딩을 더한 값을 입력한다. 마찬가지로 디코더 역시 입력 값을 바로 입력하는 것이 아니라 위치 인코딩을 추가한 값을 디코더의 입력값으로 사용한다
아래의 그림과 같이 각 시간 단계의 입력을 임베딩으로 변환한다고 할 때 (여기서는 이전 시간 단계에서 디코더가 생성한 단어의 임베딩을 계산하므로 출력 임베딩(output embedding)이라고 위치 인코딩 값을 추가한 다음 디코더에 입력한다

그렇다면 디코더의 작동한 작동 원리는 무엇일까?
하나의 디코더 블록은 다음과 같은 요소들로 구성된다

디코더 블록은 서브레이어 3개로 구성된 인코더 블록과 유사한 구조다
- 마스크된 멀티 헤드 어텐션
- 멀티 헤드 어텐션
- 피드포워드 네트워크
Masked Multi-Head Attention
영어를 프랑스어로 번역하는 태스크가 있고, 학습 데이터가 다음과 같이 준비되어 있다고 가장하자
| 입력 문장 | 타킷 문장 |
| I am good | Je vais bien |
| Good morning | Bonjour |
| Thank you very much | Merci beaucoup |
위의 데이터를 통해 번역 태스크의 입력과 출력 형태를 이해할 수 있다. 앞에서 번역 모델에 대한 테스크를 수행할 때 디코더에서 타킷 문장을 어떻게 생성하는지 알아봤다
모델을 학습할 때는 이미 타킷 문장을 알고 있어서 디코더에 기본으로 타킷 문장 전체를 입력하면 되지만 수정 작업이 조금 필요하다. 디코더에서 문장을 입력할 때 처음에는 <sos> 토큰을 입력하고 <eos> 토큰이 생성될 때까지 이전 단계에서 예측한 단어를 추가하는 형태로 입력을 반복한다. 따라서 타킷 문장의 시작 부분에 <sos> 토큰을 추가한 다음 디코더에 입력한다
'I am good' 을 'Je vais bien'으로 번역한다고 가정해보자. 타킷 문장 시작 부분에 <sos> 토큰을 추가한 '<sos> Je vais bien' 을 디코더에 입력하면 디코더에서 'Je vais bien<eos>' 를 출력한다

그렇다면 세부적으로 어떤 방식으로 작동하는 것일까? 왜 타킷 문장 전체를 입력하고 디코더에서는 한 단계 이동한 형태의 문장을 출력하는 것일까?
디코더에 입력 문장을 입력할 때 입력 문장을 임베딩(출력 임베딩 행렬)으로 변환한 후 위치 인코딩을 추가해 디코더에 입력하는 것을 알 고 있다. 디코더의 입력 행렬을 X라고 하자

행렬 X를 디코더에 입력하면 첫 번째 레이어는 마스크된 멀티 헤드 어텐셔( masked multi-head attention)이 된다. 인코더에서 사용한 멀티 헤드 어텐션과 기본 원리는 같지만 다른 점이 한가지 있다
셀프 어텐션을 구현하면 처음에 쿼리 (Q), 키 (K), 밸류(V) 행렬을 생성한다. 멀티 헤드 어텐션을 계산하면 h개의 쿼리, 키, 밸류 행렬을 생성한다. 따라서 헤드 i의 경우 행렬 X에 각각 가중치 행렬 \(W^Q_1\), \(W^K_1\), \(W^V_1\)을 각각 곱해 쿼리 \((Q_1)\), 키 \((K_1)\), 밸류 \((V_1)\) 행렬을 얻을 수 있다.
이제 마스크된 멀티 헤드 어텐션을 살펴보자. 디코더의 입력 문장은 '<sos> Je vais bien' 이다. 앞에서 셀프 어텐션은 각 단어의 의미를 이해하기 위해 각 단어와 문장 내 전체 단어를 연결했다. 그런데 디코더에서 문장을 생성할 때 이전 단계에서 생성한 단어만 입력 문장으로 넣는다. 그런데 디코더에서 문장을 생성할 때 이전 단계에서 새성한 단어만 입력 문장으로 넣는다는 점이 중요하다. 예를 들어 t=2의 경우 디코더의 입력 단어는 [<sos>, je]만 들어간다. 즉, 이런 데이터의 특성을 살려 모델 학습을 진행해야 한다. 따라서 셀프 어텐션은 단어와의 연관성을 'Je'만 고려해야 하며, 모델이 아직 예측하지 않은 오른쪽의 모든 단어를 마스킹해 학습을 진행한다
<sos> 다음 단어를 에측한다고 하자. 이와 같은 경우 모델은 <sos>까지만 볼 수 있어서 <sos> 오른쪽에 있는 모든 단어에 마스킹 작업을 한다. 그 다음으로 'Je' 단어를 예측한다고 하자. 이때 모델은 'Je'까지의 단어만 표시하므로 'Je' 오른쪽에 있는 모든 단어를 마스킹한다. 지금까지 설명한 내용은 아래의 그림에서 볼 수 있다

이와 같은 단어 마스킹 작업은 셀프 어텐션에서 입력되는 단어에만 집중해 단어를 정확하게 생성하는 긍정적인 효과를 가져온다.
그렇다면 마스킹은 어떻게 구현할 수 있을까?
$$ Z_1 = softmax\left ( \frac{Q_iK_i^T}{\sqrt{d_k}} \right )V_i $$
어텐션 행렬을 구한느 첫 번째 단계는 쿼리와 키 행렬 사이의 내적을 계산하는 것이다
그 다음으로 내적값을 키 벡터의 차원으로 나눈 후 행렬에 소프트 맥스 함수를 적용해 정규화 작업을 수행한다
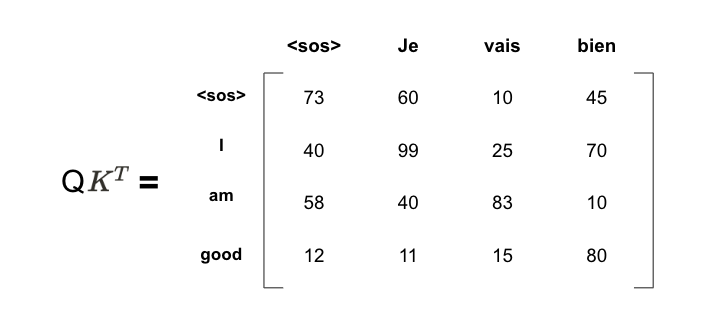
그 다음으로 쿼리와 키 행렬을 키 벡터로 나눈 값은

위 행렬에 소프트맥스 함수를 적용하기 전에 행렬 값에 대한 마스킹 처리가 필요하다. 예를 들어 위 행렬의 첫 번째 행을 보면 <sos>의 다음 단어를 에측한다고 할 때 모델에서는 <sos> 오늘쪽에 있는 모든 단어를 참조하지 말아야 한다 (텍스트 생성시 사용이 불가능하기 때문이다) <sos> 오른쪽에 있는 모든 단어를 -무한대로 마스킹을 수행한다
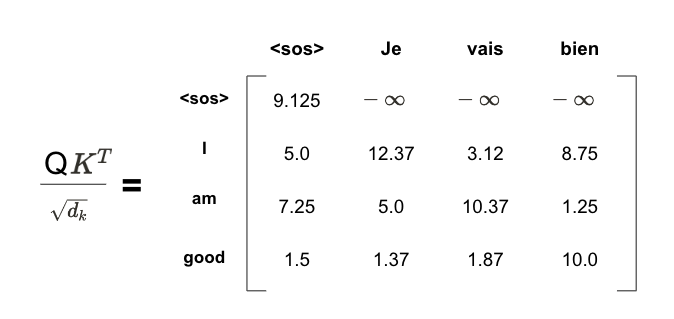
이제 두 번째 행을 보자 'Je' 다음 단어를 예측하기 위해 모델에서는 'Je' 오른쪽에 있는 단어를 참조하지 말아야 한다. 따라서 'Je' 오른쪽에 있는 모든 단어를 -무한대로 마스킹한다
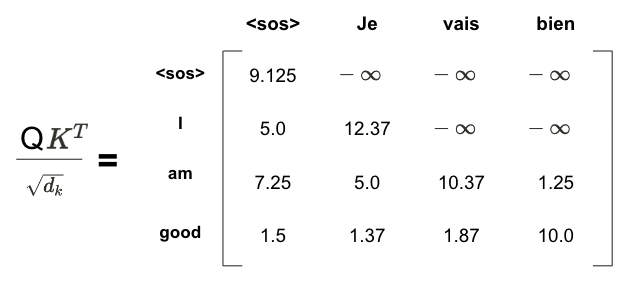
유사하게 vais 우측 단어도 동일한 형태로 처리한다

이제 소프트 맥스 함수를 적용한 행렬과 밸류 \(V_i\) 행렬에 곱해 최종적으로 어텐션 행렬 \(Z_i\)을 구한다. 멀티 헤드 어텐션의 경우 h개의 어텐션 행렬을 구하고 이들을 서로 연결한 후에 새로운 가중치 행렬 \(W^0\)를 곱해 최종적으로 어텐션 행렬을 구한다
$$ M = concatenate(Z_1, Z_2, ..., Z_h)W_0 $$
이렇게 구한 어텐션 행렬 M을 다음 서브레이어에 있는 다른 형태의 멀티 헤드 어텐션의 입력값으로 넣는다.
Multi-head Attention
인코더와 디코더를 결합한 트랜스포머 모델은 아래의 그림처럼 디코더의 멀티 헤드 어텐션은 입력 데이터 2개를 받고, 하나는 이전 서브레이어의 출력값이고, 다른 하나는 인코더의 표현이다

인코더의 표현값을 R, 이전 서브레이어인 멀티 헤드 어텐션의 결과로 나온 어텐션 행렬은 M이라고 하며, 여기서 인코더의 결과와 디코더의 결과 사이에 상호 작용이 일어난다. 이 인코더-디코더 어텐션 레이러(encoder-decoder attention layer)라고 부른다.
이제 멀티 헤드 어텐션 레이어가 어떻게 작동하는지 알아보자
첫번째 단계에서는 멀티 헤드 어텐션에서 사용하는 쿼리, 키, 밸류 행렬을 생성한다. 행렬에 가중치 행렬을 곱해서 쿼리, 키, 밸류 행렬을 만들 수 있다.
그러면 입력값이 2개 인코더 표현인 R과 이전 서브레이어의 결과인 M의 경우에는 어떻게 되는지 알아보자
이전 서브레이어의 출력값인 어텐션 행렬 M을 사용해 쿼리 행렬 Q를 생성하고, 인코더 표현 값이 R을 활용해 키, 밸류 행렬을 생성한다. 현재 멀티 헤드 어텐션을 사용하고 있으므로 헤드 i를 기준으로 다음 절차를 다른다
- 어텐션 행렬 M에 가중치 행렬 \(W^Q_i\)를 곱해 쿼리 행렬 \(Q_i\)를 생성한다.
- 인코더 표현값 R에 가중치 행렬 \(W^K_i\), \(W^V_i\) 를 각각 곱해 키, 밸류 행렬 \(K_i\), \(V_i\)를 생성한다
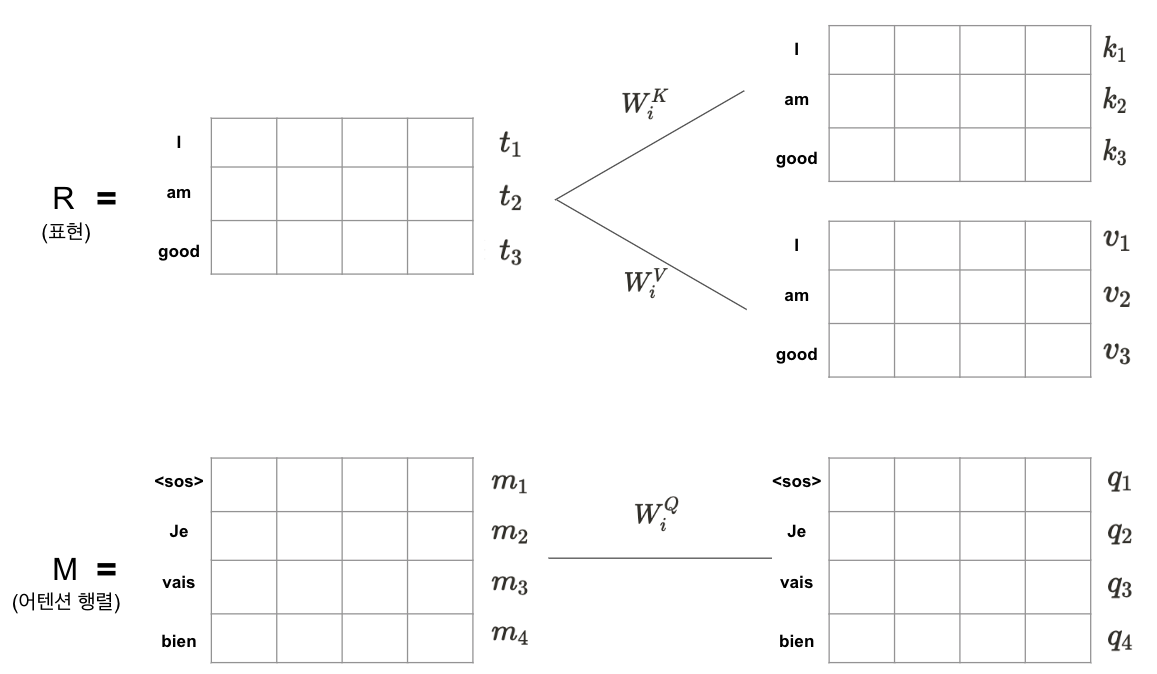
왜 쿼리 행렬은 M을 통해 생성하고 키, 밸류 행렬은 R을 통해 생성하는 것일까? 일반적으로 쿼리 행렬은 타킷 문장의 표현을 포함하므로 타킷 문장에 대한 값인 M의 값을 참조한다. 키 와 밸류 행렬은 입력 문장의 표현을 가져서 R의 값을 참조한다.
셀프 어텐션의 첫 번째 단계는 쿼리, 키 행렬 간의 내적을 계산하는 것이다.

쿼리, 키 행렬 간의 내적을 구한 결과는
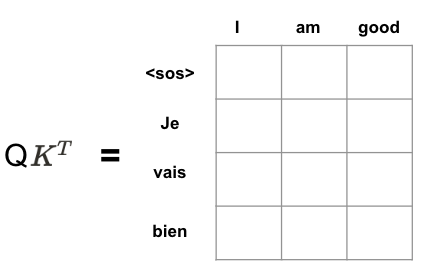
멀티 헤드 어텐션의 다음 단계는 쿼리와 키를 밸류의 차원으로 나눈 것이며, 이후 소프트 맥스 함수를 사용하면 다음과 같은 스코어를 얻을 수 있다.
$$ Z_1 = softmax\left ( \frac{Q_iK_i^T}{\sqrt{d_k}} \right )V_i $$

이처럼 h개의 헤드에 대해 어텐션 행렬을 구한 후 이를 연결하고, 가중치 행렬 \(W^0 \)를 곱하면 최종 어텐션 행렬을 구할 수 있다.
$$ multi-head \; attention = concatenate(Z_1, Z_2, ..., Z_h)W_0 $$
Transforemr Attention 참조
transformer에서 사용되고 있는 Encoder self-attetion, Masked decoder self-attention, Encoder-Decoder Attention 에 대한 시각화 자료
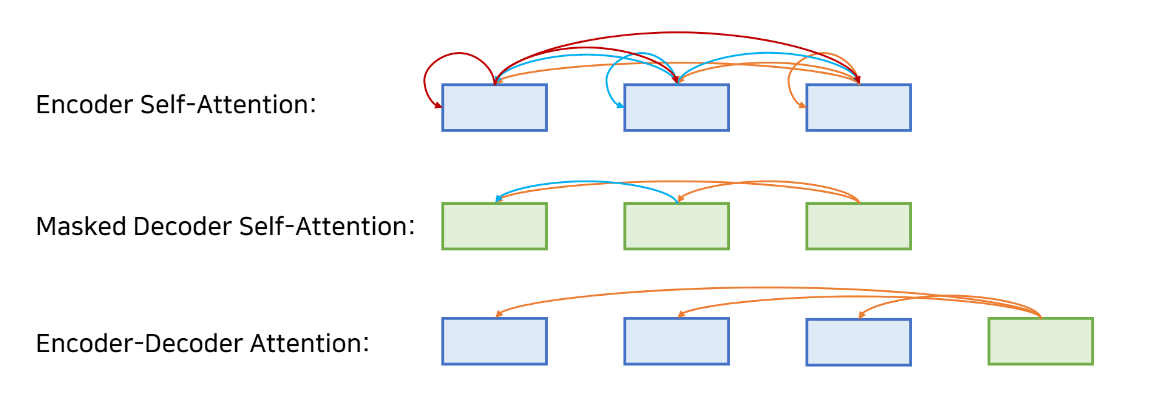
https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
참고자료
- 구글 BERT의 정석
'Machine-Learning > NLP (Natural Language Processing)' 카테고리의 다른 글
| [ML] GLUE (General Language Understanding Evaluation) (0) | 2022.11.30 |
|---|---|
| [NLP] BERT 의 이해 (0) | 2022.11.19 |
| [NLP] 멀티 헤드 어텐션(multi-head attention) 원리 (2) | 2022.11.06 |
| [NLP] Transforemr - 피드포워드, add와 Norm (0) | 2022.11.06 |
| [NLP] Transformer - positional encoding, self-attention (0) | 2022.10.11 |




댓글